
Bonjour a tous
Dans cet article nous allons voir comment utiliser la transformation de multidiffusion dans Un package SSIS
Scénario:
Parfois, nous avons besoin de lire les données d’une seul source unique, puis le charger vers plusieurs destinations ,Disons que nous avons un table A (SQL Server) comme source du données et nous devons charger un fichier plat et un deuxième table SQL Server comme destination
Solution:
Nous pouvons utiliser la transformation de multidiffusion dans SSIS. Transformation de multidiffusion prend une entrée et crée de multiples sorties. Chacun de la sortie est de la réplique entrée
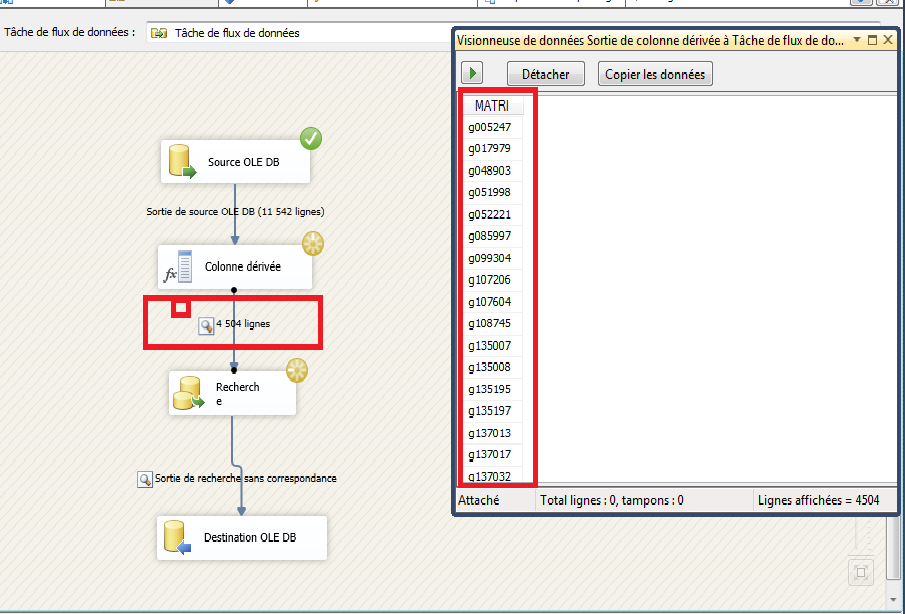
l’image explique mieux que mes mots:
Prenez ce flux très simple de données On va commencer par crée un nouveau projet SSIS . Une fois que le projet est créé, nous allons voir comment utiliser la tâche de transformation multi casting. Une fois que vous ouvrez le projet il suffit de glisser et déposez le contrôle de transformation de Moulage multi et un fournisseur de source, comme indiqué dans l’image ci-dessous

Modifier la tâche de flux de données en double cliquant sur l’objet ou en sélectionnant le bouton EDIT sur un clic droit sur l’objet. Assurez-vous que le flux de données Page est ouvert, comme indiqué ci-dessous.

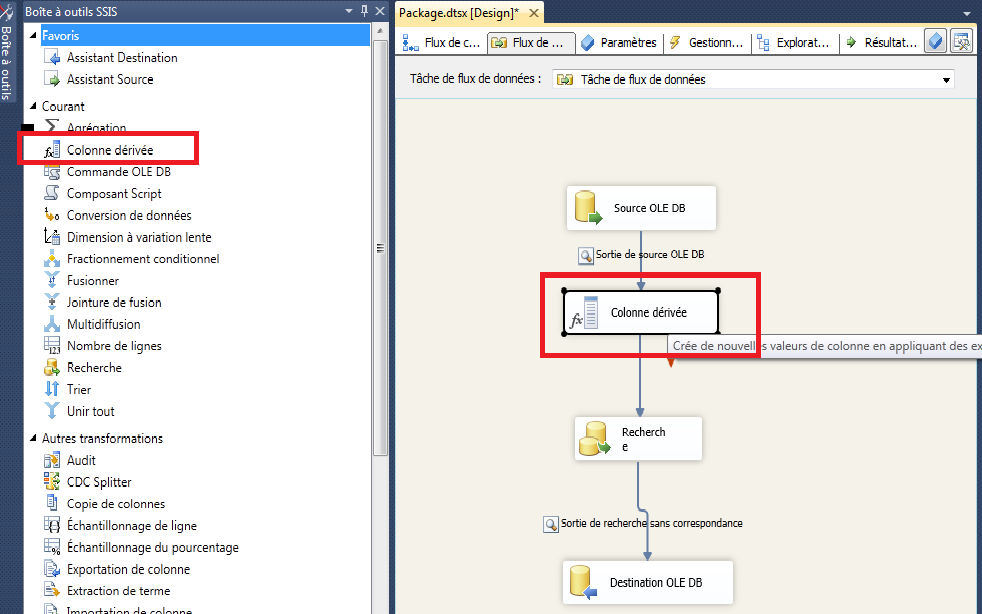
Glissez et déposez le MultiCast transformation dans le flux volet Données et offrir une connexion entre OLE DB Source et Multicast transformation, comme indiqué ci-dessous.
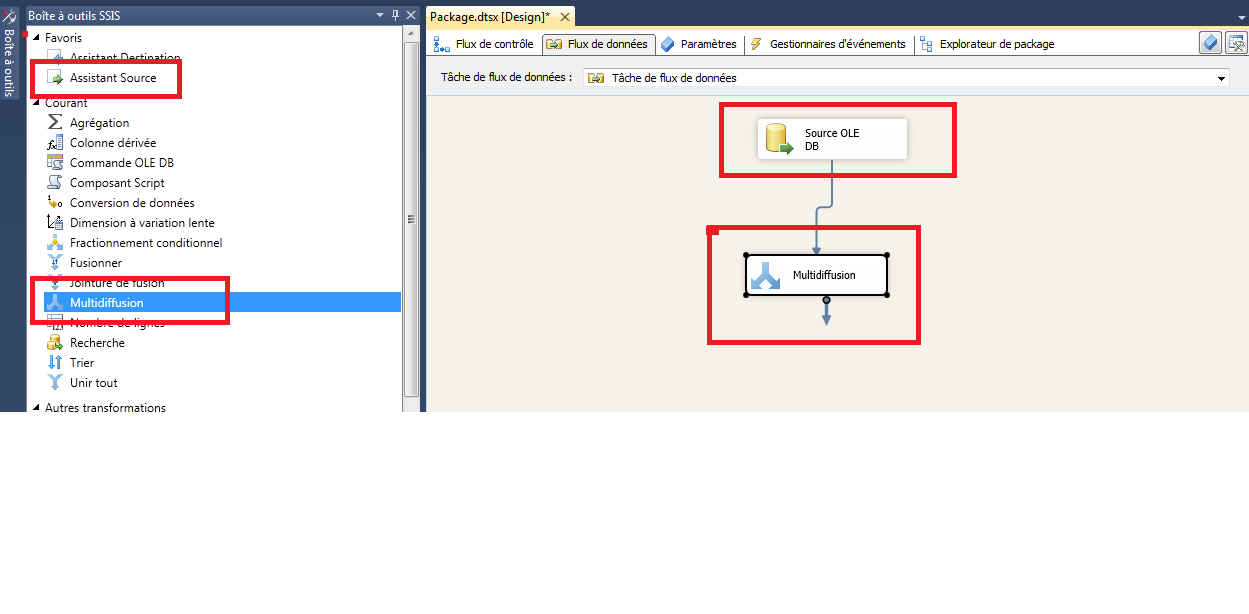
Maintenant nous devons configurer la source de données open source fournisseur OLEDB, comme indiqué dans l’écran ci-dessous

Une fois que la source est configuré maintenant glisser et déposer 2 destinations comme indiqué dans l’écran ci-dessous
1 – tâche de fournisseur OLEDB de mettre à jour la table
2 – fournisseur de fichier plat de mettre à jour un fichier
3 – fournisseur Excel de mettre à jour un fichier Excel



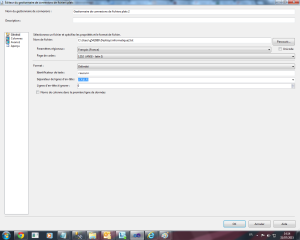
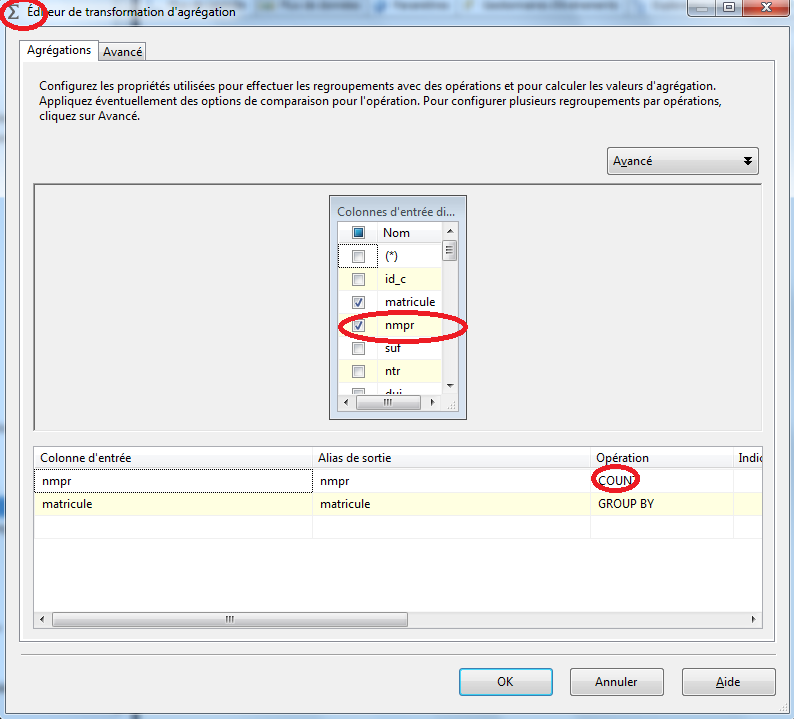
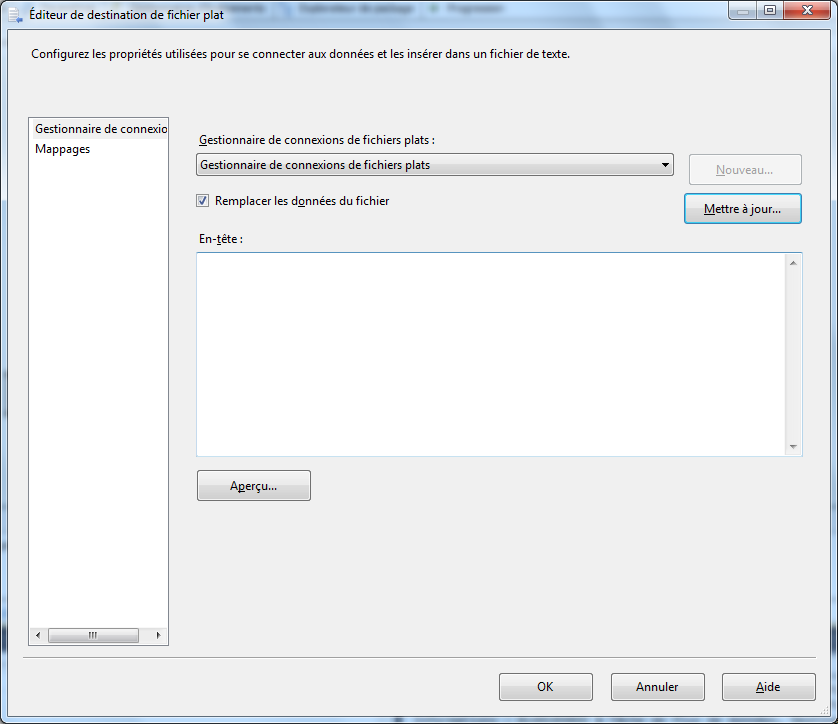
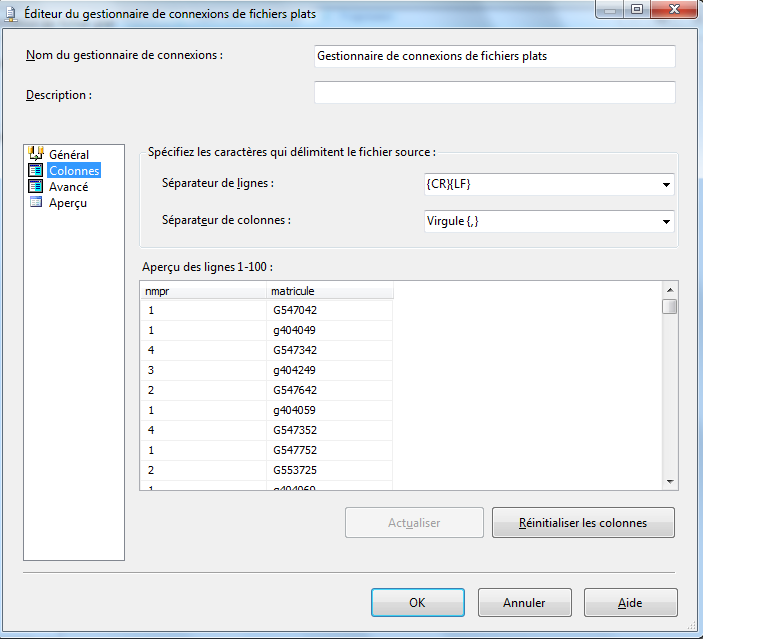
Maintenant, nous allons configurer le fournisseur de fichier plat comme indiqué dans l’écran ci-dessous
- Vérifiez les mappings et cliquez sur OK.

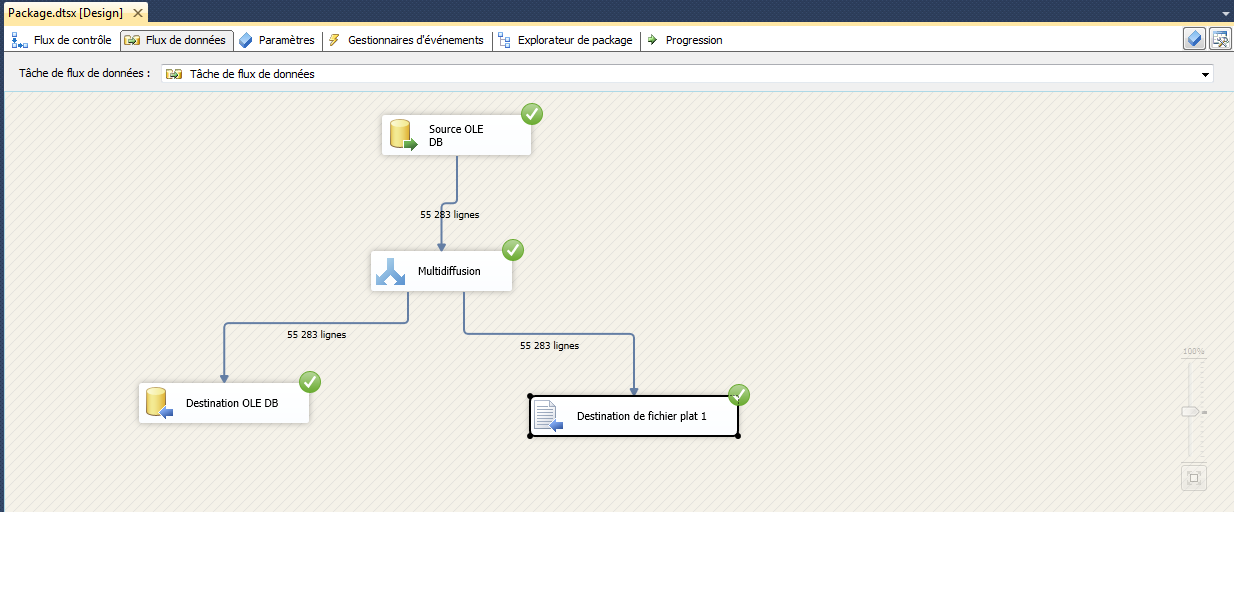
Une fois que tout est configuré votre écran devrait ressembler à l’écran ci-dessous
Maintenant, le paquet est prêt à exécuter. Appuyez sur F5 et vous pouvez voir l’écran ressemble à ci-dessous qui indique que l’exécution est terminée

























{kind=link}