Bonjour
Auparavant, j’ai écrit un article sur la conception et la mise en œuvre d’un UPSERT LOOKUP qui concerne la mise à jour des enregistrements existants et l’insertion de nouveaux enregistrements. Aujourd’hui, je souhaite également étendre cela en ajoutant l’opération de suppression Ainsi, la méthode utilisée dans cet article peut être utilisée pour trouver des enregistrements INSERTED / UPDATED / DELETED à partir de la table source et appliquer ces modifications à la table de destination.
Dans cet exemple, j’ai utilisé la transformation de jointure de fusion, le fractionnement conditionnel et la transformation de commande OLE DB pour implémenter la solution
Tout d’abord, nous appliquons une jointure externe complète sur la table source et de destination dans la ou les colonnes clés avec la transformation Fusion de jointure. Nous utilisons ensuite une division conditionnelle pour déterminer le type de modification (enregistrements supprimés, nouveaux ou existants). Les enregistrements existants nécessiteront un autre traitement pour savoir s’il y a eu des changements ou non? Nous utilisons un autre fois le fractionnement conditionnel pour comparer la valeur des colonnes équivalentes dans la source et la destination
Je montrerai donc comment synchroniser ces données entre serverA et serverB en utilisant une jointure de fusion dans SSIS
Voici à quoi ressemble mon package SSIS. Je vais discuter de chacune des étapes

J’ai deux sources OLE DB, une pour serverA (source) et l’autre pour serverB (destination). Voici comment ces connexions sont configurées
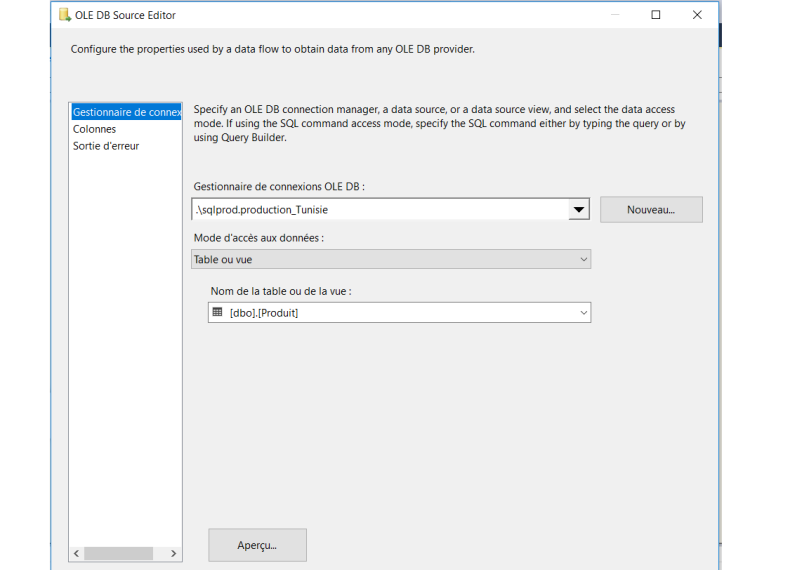
Lors de l’application d’une jointure par fusion, les données doivent être triées pour les deux entrées. J’applique donc une opération de tri des deux côtés

Maintenant Faites glisser le composant Jointure de fusion connecter Sur les deux sources OLE DB Définissez la table source comme gauche et la table de destination comme entrée droite de cette transformation.
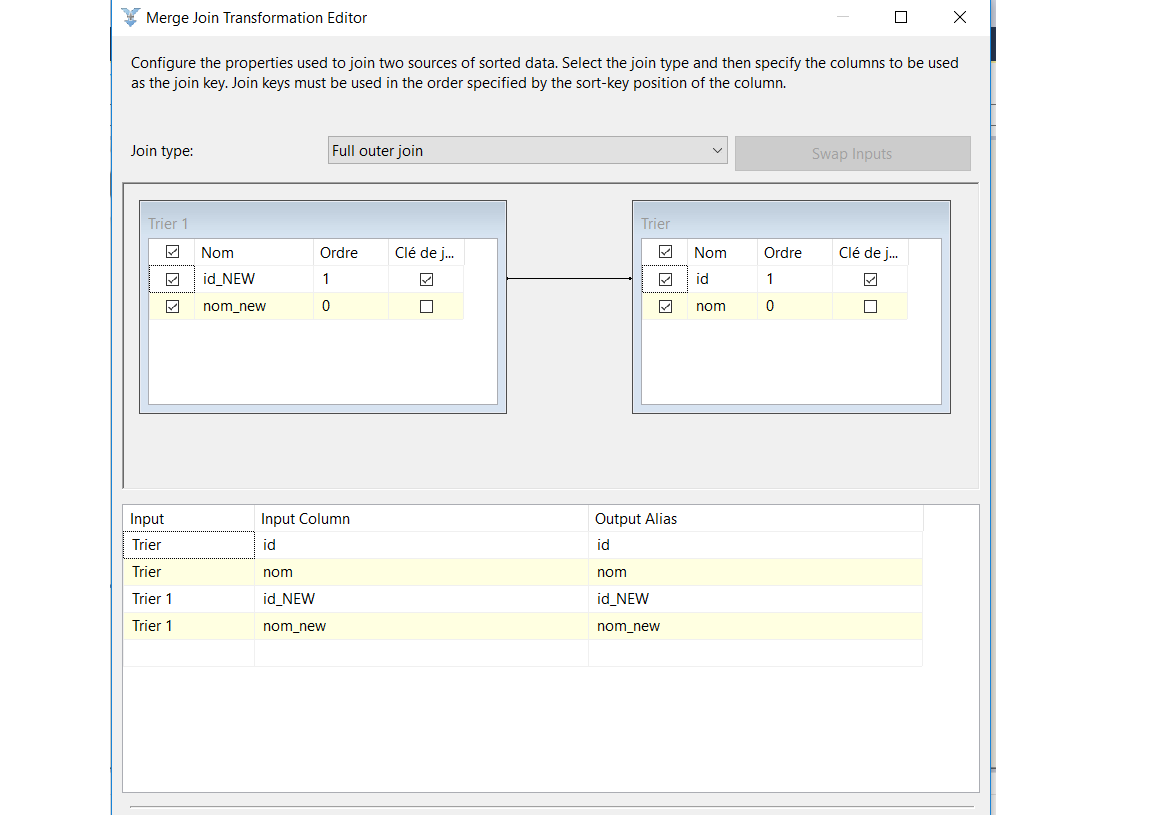
Allez dans l’éditeur du composant Jointure de fusiones , le colonne ID sera utilisé comme colonne de jointure (sélectionnée en fonction des propriétés de tri des composants précédents). Notez que si vous ne triez pas les colonnes d’entrée de la transformation de jointure de fusion, vous ne pouvez pas entrer dans l’éditeur de cette transformation et vous rencontrez l’erreur concernant le tri des entrées.
Sélectionnez toutes les colonnes des tables Source et Destination dans la transformation de jointure de fusion et renommez-les comme le montre l’image ci-dessous
À l’étape suivante, j’ai appliqué le composant Fractionnement conditionnel J’ai ajouté trois conditions différentes en fonction du résultat de la jointure externe complète. Ce sont les trois conditions:
- UPDATE (correspondance avec ID): Si le ID existe à la fois sur la source et la destination, nous effectuons une mise à jour.
- INSERT (id introuvable dans la destination): Si ID se trouve uniquement à gauche (source), nous devons insérer ces données dans la table de destination.
- DELETE (ID est introuvable dans la source): Si ID n’est pas trouvé dans la table source, nous devons supprimer ces données de la table de destination
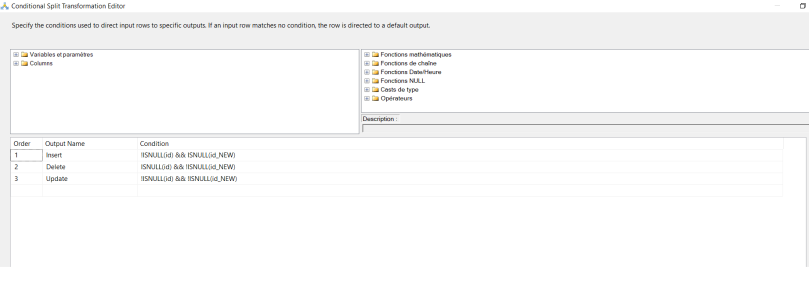

1 Insert !ISNULL(id) && ISNULL(id_NEW) 2 Delete ISNULL(id) && !ISNULL(id_NEW) 3 Update !ISNULL(id) && !ISNULL(id_NEW)
Nous avons donc maintenant trois flux de données pour effectuer une insertion, une mise à jour ou une suppression.
- Opération insert
Ajouter une destination OLE DB et connecter la sortie NEW RECORDS. Définissez la configuration de la table de destination et utilisez des colonnes avec le préfixe source dans le mappage de colonnes de la destination OLE DB. Ce composant de destination insérera de nouveaux enregistrements dans la table de destination
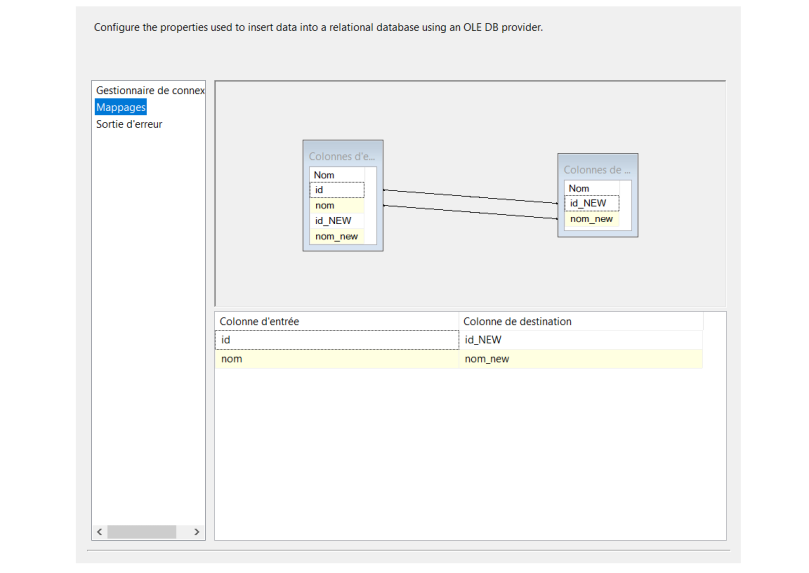
- Opération delete
Pour supprimer des données, j’ai une connexion de destination OLE DB et j’ai ajouté une commande sql comme suit à l’aide de l’éditeur avancé
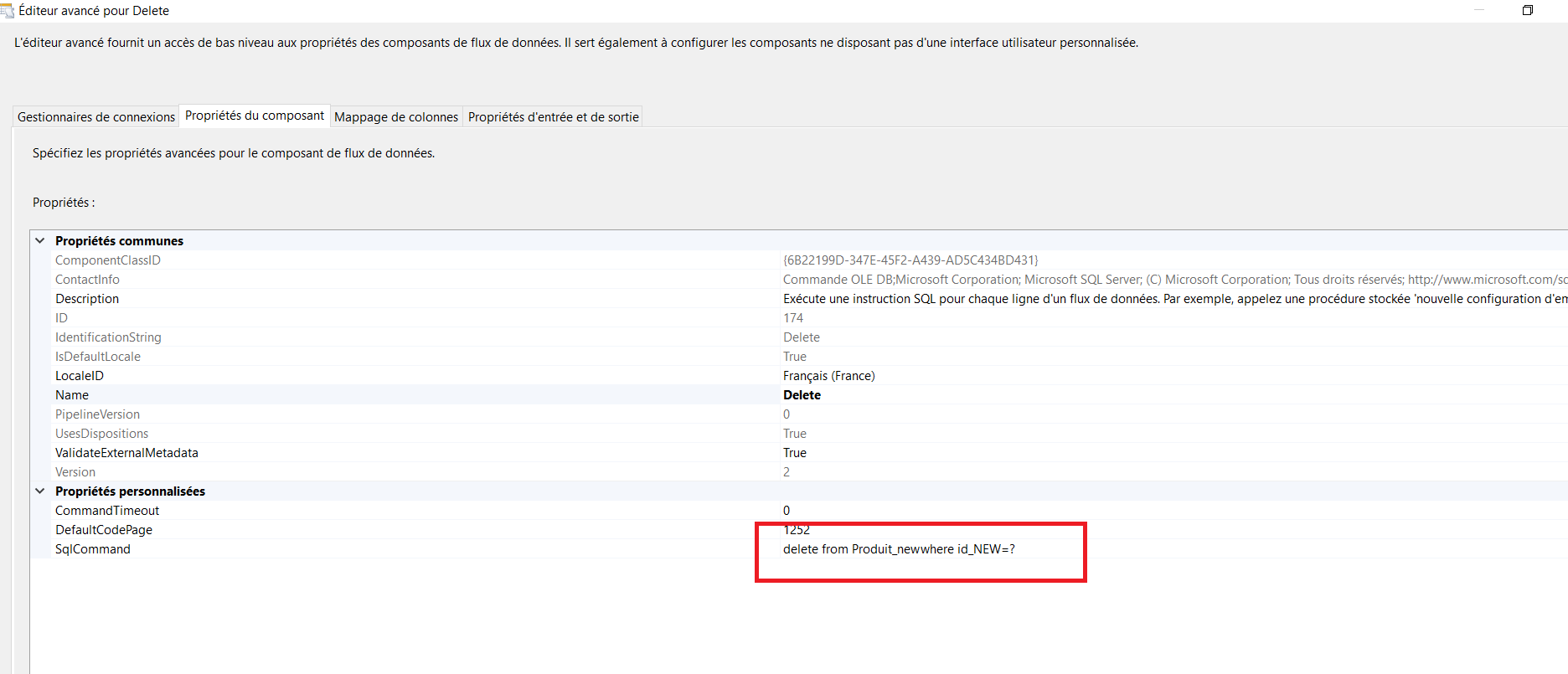

delete from Produit_new where id_NEW=?
- Opération Update
Ajouter de nouveau le composant Fractionnement conditionnel Nous utilisons ce composant pour rechercher uniquement les enregistrements qui ont changé dans l’une des valeurs. Nous comparons donc les colonnes source et destination équivalentes pour trouver des données non correspondantes.C’est l’expression utilisée pour trouver les données de correspondance dans la capture d’écran ci-dessous

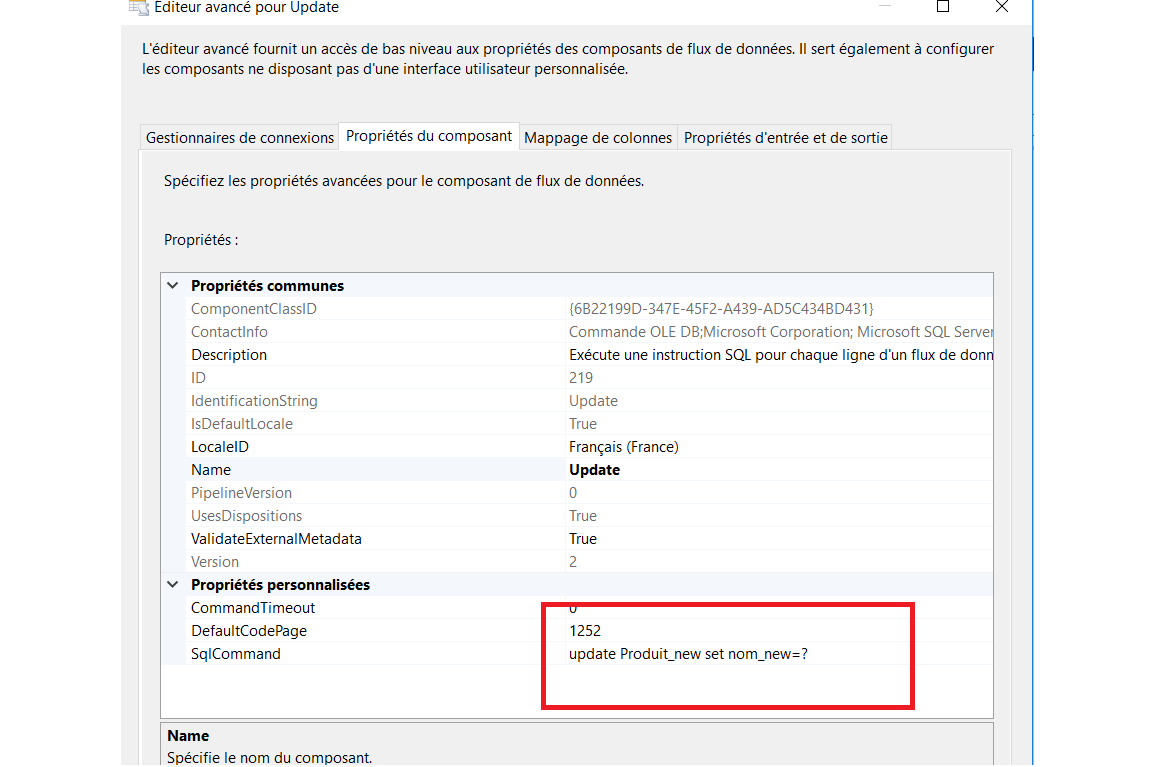
Après avoir lancé la commande avec le paramètre «?», J’ai ensuite appliqué le mappage de colonne d’entrée avec les colonnes de destination de paramètres disponibles en fonction de la table de destination

Exécution du package
Après avoir configuré toutes les étapes ci-dessus, en changeant au hasard certaines des données, je lance alors le package et obtient les éléments suivants

Conclusion
la synchronisation a été bien passer entre la table source et la destination en effectuant des opérations d’insertion, de mise à jour et de suppression avec des données de la source vers la destination