bonjour,
Plusieurs fois, notre base de données contient des lignes en double qui peuvent être filtrées en utilisant certaines colonnes. Un développeur devait supprimer ces lignes dupliquées avec une requête TSQL nous avons vu ensemble dans l’ancien article comment le faire a travers SSIS a travers le composant Tri Suppression les lignes dupliquées avec SSIS
Ici, je montre un moyen simple de supprimer les lignes en double
j’utilise le table [ProductCategory] du base AdventureWorks 2014

Le CTE commence par le mot « With » suivi d’un nom d’expression et de noms de colonnes. Ensuite, la requête de sélection qui remplit l’expression. Nous pouvons avoir plusieurs ensembles d’expression séparés par une virgule suivie de l’instruction finale. Nous n’entrons pas dans les détails de CTE car cela est hors de portée de cet article. Voyons comment nous pouvons utiliser CTE pour supprimer les lignes en double. Regardez le code ci-dessous:
with cte as ( select row_number()over (partition by ParentProductCategoryID,Name order by ParentProductCategoryID ) as classement, ParentProductCategoryID,Name from [SalesLT].[ProductCategory] where ParentProductCategoryID is not null )delete from cte where classement >1
Autre Méthode
delete from SalesLT.ProductCategory
where ParentProductCategoryID in
(select ParentProductCategoryID from SalesLT.ProductCategory group by ParentProductCategoryID
having
count(*) >1
Après l’exécution, ces codes affichent les données de la table, toutes les lignes uniques sont présentes
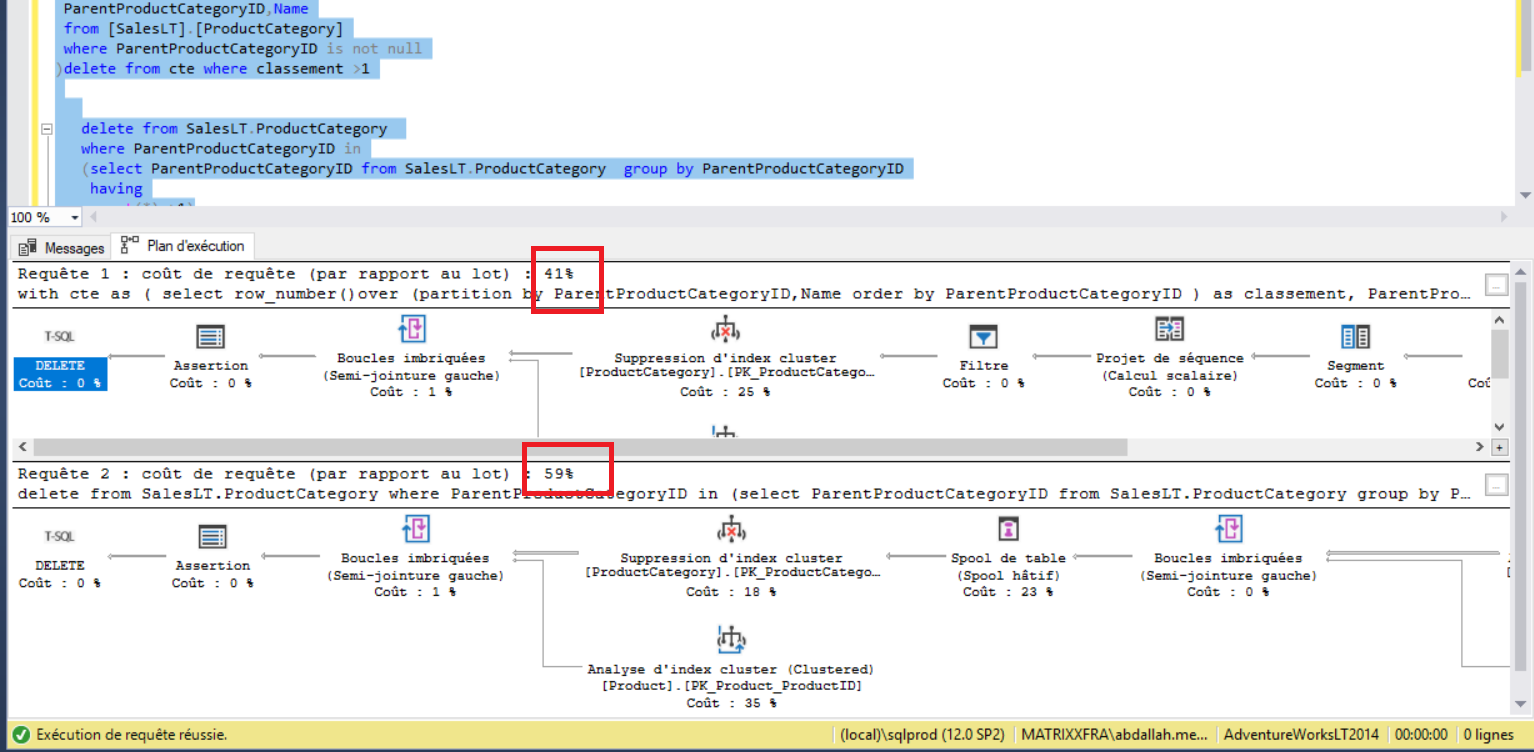
les deux méthode Fonctionne correctement mais si en fait une petit comparaison en terme performance avec le CTE il est plus performant il a le coût le plus bas
En supprimant les données et en examinant à nouveau les plans d’exécution, nous constatons que le plus rapide est la première commande DELETE et que la plus lente est la dernière, comme prévu