bonjour a tous
SQL Server 2008 a introduit une nouvelle fonction de suivi puissant et efficace appelés «Suivi des modifications (CT) » et capture de données modifiées (CDC) ——->change Traicking
Dans cet article, on va voir comment activer cette fonctionalité et comment l’utiliser le CT est une nouvelle fonctionnalité de SQL Server 2008 qui nous permet de suivre les informations sur les modifications que nous avons apportées aux tables où CT est activée.
Lorsque cette option est activée pour une table, elle permet de conserver une trace de chaque opération DML et les touches de la rangée qui a été touchée. Cela signifie que, à tout moment, nous pouvons interroger pour savoir quelles lignes dans notre table (s) ont été insérés / supprimé / mise à jour
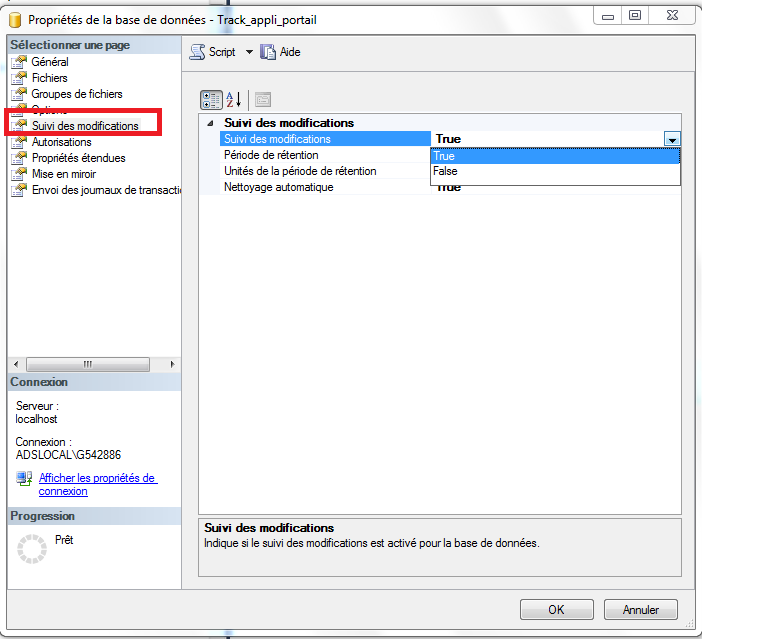
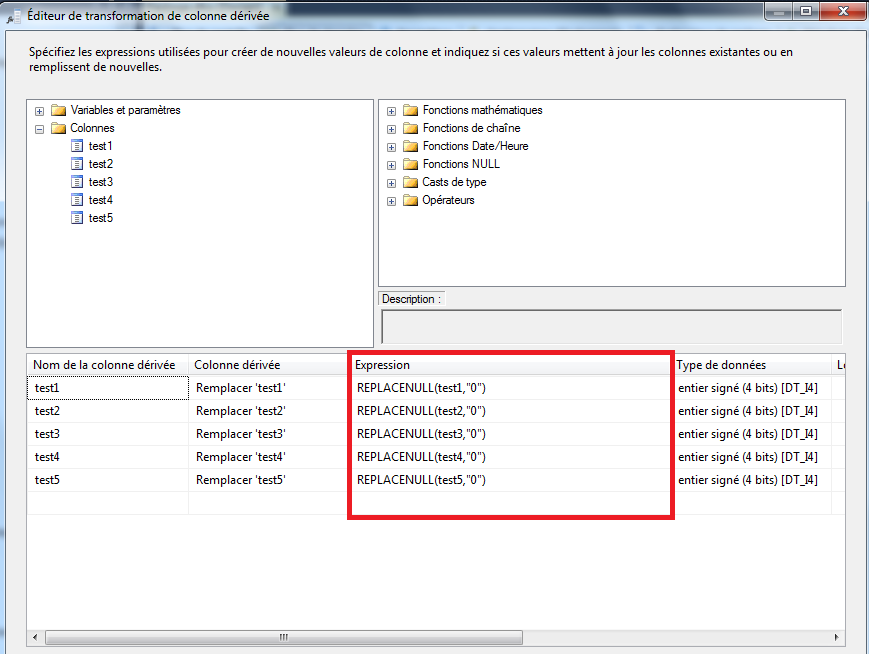
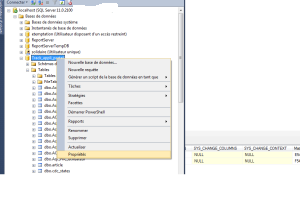
Si nous voulons travailler avec le CT, nous devons activer le CT sur notre base de données et les liste des tables sur lesquelles nous sommes intéressés à suivre les changements. Nous ne pouvons pas permettre à CT pour la table sans activer CT pour la base de données. Alors, faut d’abord activer CT pour la base de données, puis pour la table comme le montre la capture d’écran ci-dessous:on fait un clique droit sur la base puis propriété puis on fait le chois sur le bouton suivi de modification
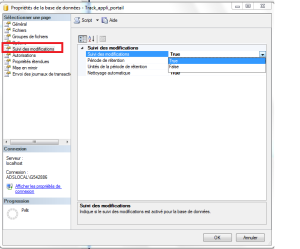
En T SQL
USE [master]
GO
ALTER DATABASE [Track_appli_portail] SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 3 DAYS)
GO
maintenant on procède a l’activer pour une table en utilisant SSMS en sélectionnant Propriétés de table> Suivi des modifications, comme le montre la capture d’écran ci-dessous:
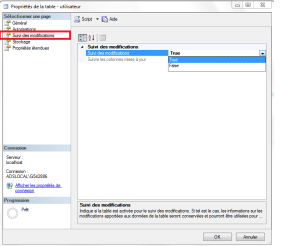
USE [Track_appli_portail]
GO
ALTER TABLE [dbo].[utilisateur] ENABLE CHANGE_TRACKING
GO
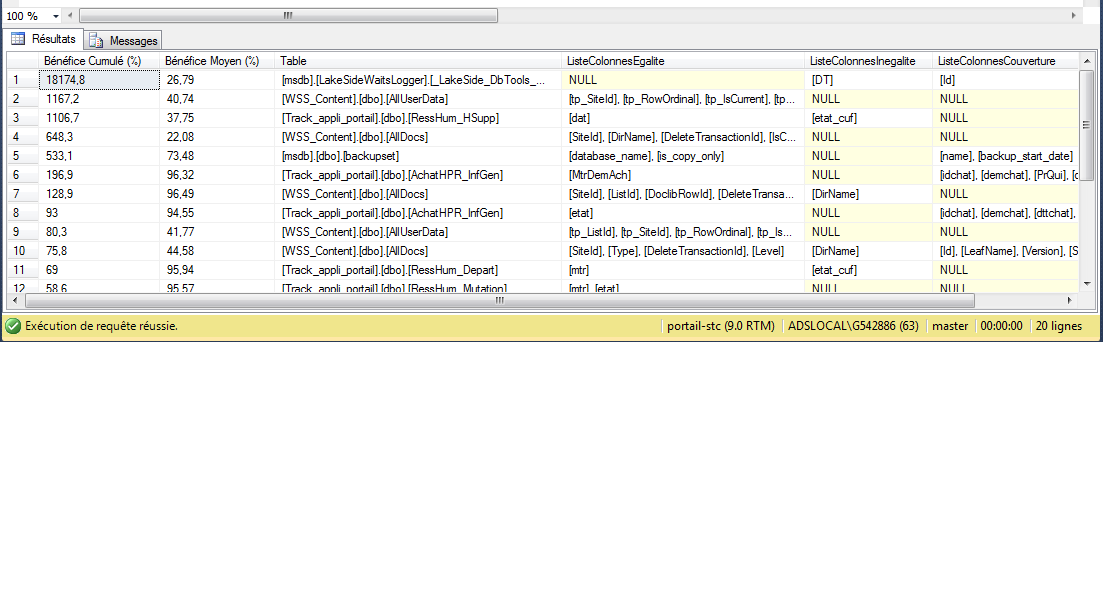
pour récupérer les données modifiées on va utilisé une fonction appelées CHANGETABLE ,La fonction CHANGETABLE a deux paramètres. Le premier paramètre est de fournir le nom de la table. CHANGES est un mot clé que vous devez inclure pour récupérer les changements. Une autre option VERSION sera discuté plus tard
Le second paramètre est le numéro de version. Le numéro de version sera maintenue entre la base de données. Pour une seule opération sur une table qui a suivi des modifications le numéro de version sera incrémenté. Par exemple, après l’activation du suivi des modifications, le numéro de version sera 0 et après l’insertion d’enregistrements dans le tableau A le numéro de version sera 1 et d’effectuer les mises à jour se traduira par un numéro de version 2.
Si vous passez 0 comme paramètre de version, vous obtiendrez toutes les modifications qui ont été faites après la version 0 qui signifie que toutes les modifications après l’activation du suivi Change. La chose importante à noter ici est que vous obtiendrez les variations nettes, ce qui est très pratique pour l’entreposage de données. la fonction la plus importante est CHANGE_TRACKING_CURRENT_VERSION. Cela renvoie la version actuelle après la dernière transaction validée au niveau de la base de données. pour connaitre il faut taper cette requêtes :SELECT CHANGE_TRACKING_CURRENT_VERSION()
Maintenant on va procéder a faire quelque opération d’insertion,mise a joue,suppression….
faisant maintenant l’exécution de cette requête et voir la résultat
SELECT * FROM CHANGETABLE(CHANGES dbo.utilisateur,0)as résultat
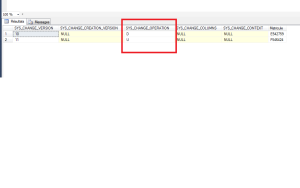
SELECT SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION,matricule
FROM CHANGETABLE(CHANGES dbo.utilisateur,0)AS ET
ORDER BY SYS_CHANGE_VERSION
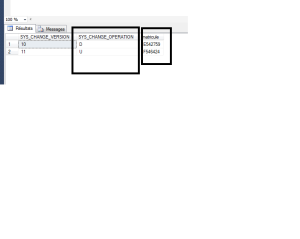
Dans ce tableau on explique la définition de chaque colonne
| Nom de la colonne |
Description |
| SYS_CHANGE_VERSION |
Il représente le dernier numéro de version quand une ligne particulière a été mise à jour. |
| SYS_CHANGE_CREATION_VERSION |
Il représente le numéro de version lorsqu’un enregistrement a été inséré. Il ne sera pas écrasée comme dans le cas de SYS_CHANGE_VERSION. |
| SYS_CHANGE_OPERATION |
Il représente les opérations DML (I = INSERT, UPDATE et U = D = DELETE) |
| SYS_CHANGE_COLUMNS |
Elle représente toutes les colonnes touchées depuis la version dernière de référence. Cette colonne devra valeurs seulement pour les opérations UPDATE et si les colonnes ne sont pas affectés lors de la mise à jour, il aura la valeur NULL. |
|
Il représente les colonnes de clé primaire de votre table user suivis. Vous pouvez rejoindre votre table user suivis avec ces colonnes pour obtenir des données seulement changé à partir de la table user suivis. |
Je espère que vous avez apprécié l’apprentissage CT ? N’hésiter a activer cette fonctionnalité sur vos base de production
cordialement
..