Un détail à noter sur l’autovacuum c’est qu’il ne restitue pas l’espace qu’il libère dans le système d’exploitation. Au lieu de cela, il ne marque que l’espace comme libre, de sorte qu’il peut être utilisé plus tard de nouvelles lignes. Cela signifie que si vous avez un volume de 100 Go et que vous en supprimez la moitié, il occupera tout de même 100 Go, même si vous exécutez VACUUM dessus. Pour contourner ce problème, Postgres a une commande VACUUM FULL .
VACUUM FULL prend une table existante et crée une nouvelle copie de la table. Cela permettra au système d’exploitation de récupérer tout l’espace libre utilisé auparavant par les lignes, mais il présente quelques inconvénients. L’implémentation actuelle de VACUUM FULL verrouille complètement la table en cours d’aspiration. Cela signifie que vous ne pourrez pas exécuter de requêtes ni insérer de données dans la table tant que VACUUM FULL n’est pas terminé. En général, si vous voulez récupérer tout l’espace vide d’une table, au lieu d’utiliser VACUUM FULL , vous devriez regarder pg_repack . L’extension pg_repack est une extension Postgres qui fournit une commande équivalente à VACUUM FULL cela vous permet toujours d’exécuter des requêtes sur la table en cours de compactage
create table Test_vacumm (a int , b varchar(50), c varchar(80));
insert into test_vacumm (a,b,c) select 1, md5('abdallah'::varchar), md5('abdallah'::varchar) from generate_series ( 1, 60000000 ) ;
INSERT 0 10000000
en lançant une requête de delete massive
delete from test_vacumm;
DELETE 60000000
j’utilise cette petit requête
delete from test_vacumm;
Pour récupérer les taille des différent table dans ma base de donnée
SELECT N.nspname || '.' || C.relname AS "relation",
CASE WHEN reltype = 0
THEN pg_size_pretty(pg_total_relation_size(C.oid)) || ' (index)'
ELSE pg_size_pretty(pg_total_relation_size(C.oid)) || ' (' || pg_size_pretty(pg_relation_size(C.oid)) || ' data)'
END AS "size (data)",
COALESCE(T.tablespace, I.tablespace, '') AS "tablespace"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
LEFT JOIN pg_tables T ON (T.tablename = C.relname)
LEFT JOIN pg_indexes I ON (I.indexname = C.relname)
LEFT JOIN pg_tablespace TS ON TS.spcname = T.tablespace
LEFT JOIN pg_tablespace XS ON XS.spcname = I.tablespace
WHERE nspname NOT IN ('pg_catalog','pg_toast','information_schema')
ORDER BY pg_total_relation_size(C.oid) DESC;
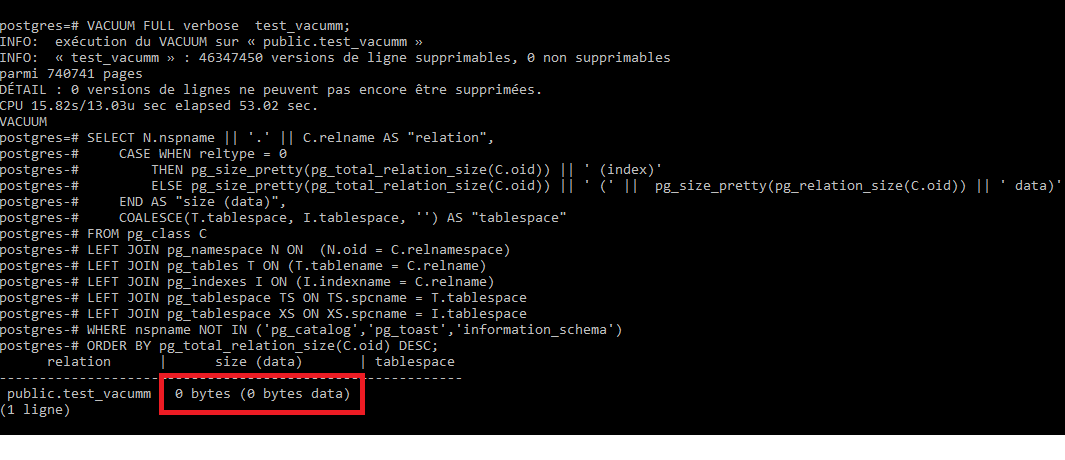
alors j’obtiens cette résultat

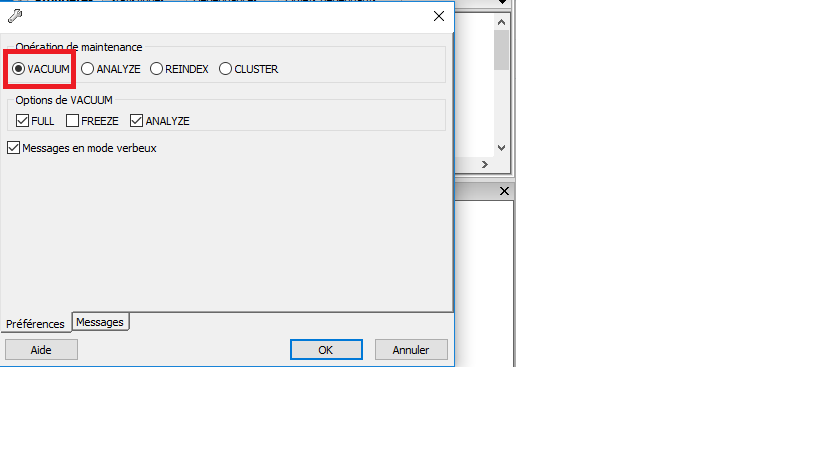
En lançant un vacuum FULL
VACUUM FULL verbose test_vacumm;
INFO: exécution du VACUUM sur « public.test_vacumm »
INFO: « test_vacumm » : 46347450 versions de ligne supprimables, 0 non supprimables
parmi 740741 pages
DÉTAIL : 0 versions de lignes ne peuvent pas encore être supprimées.
CPU 15.82s/13.03u sec elapsed 53.02 sec.
N’oubliez pas que VACUUM FULL nécessite un verrou exclusif sur la table afin que, pendant cette opération, votre table ne soit pas accessible.
aussi vous avez évidemment besoin d’un espace de stockage supplémentaire. il doit être au moins deux fois plus grand que la taille du table en question,. Si vous avez de la chance pouvez ajouter dynamiquement un disque à la machine