Bonjour
Dans cet article, nous allons mettre en place la réplication sur SQL Server 2016 . La réplication consiste en un transfert des données d’un serveur vers un ou plusieurs autres serveurs SQL
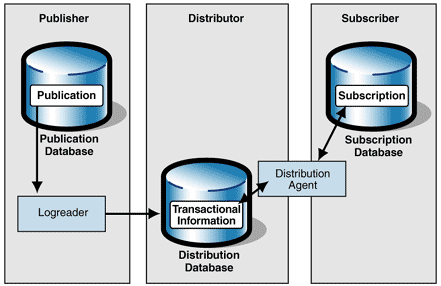
De manière générale, la réplication nécessite trois éléments clefs (fonction du type de réplication :
· Un serveur de publication : serveurs qui rendent leur donnée accessible à la réplication
· Un serveur de distribution : serveurs qui distribuent les données à répliquer
· Et des abonnées bien sûr : les serveurs de destinations des données répliquées.
1-Mise en œuvre du distributeur
SQL Server Management Studio propose différent assistant graphiques pour mettre en place, surveiller et paramétrer l’environnement de réplication
Tous ces éléments sont accessibles depuis le nœud Réplication de l’explorateur d’objets de SQlSMO
La mise en place d’un distributeur demande des privilèges d’administrateur c’est-à-dire être membre de sysadmin
*sélectionner le choix Configurer la distribution dans le menu contextuel associé au nœud Réplication

L’assistant suivant permet de création d’une publication est alors exécuté et cet assistant permet de sélectionner / configurer un distributeur pour la réplication Cet assistant va tout d’abord demander de préciser le serveur qui va jouer le rôle de distributeur

Il est alors possible de sélectionner le serveur qui hébergera également la publication (éditeur/distributeur) ou bien de sélectionner un distributeur distant
A l’étape suivante, l’assistant permet de spécifier le dossier utilisé pour les fichiers de capture instantanés. Un dossier local est proposé par défaut Si la réplication doit être accessible depuis le réseau, il est nécessaire de préciser un nom de chemin réseau

Puis L’assistant permet de préciser le nom de la base de distribution ainsi que l’emplacement Physique du fichier de donnée et du journal Comme le montre l’écran ci-dessous la base se nomme par défaut distribution et les dossiers proposés sont ceux spécifiés par défaut
Enfin, l’assistant offre la possibilité de réaliser le paramétrage immédiatement avec une fenêtre qui montre la bonne configuration

Enfin, l’assistant offre la possibilité de réaliser le paramétrage immédiatement avec une fenêtre qui montre la bonne configuration

Le menu contextuel propose de visualiser la propriété du serveur de distribution elle permet aussi de désactiver la distribution Toujours depuis l’explorateur d’objets, il est possible de visualiser la base de données système distribution qui a été créé à l’aide de l’assistant

2-Création de la publication
Au moment de la création d’une publication les éléments suivantes doivent être spécifiés lors de l’éxecution de l’assistant de création
*le Type de Réplication (capture instantané, Transactionelle ou fusion)
L’activation de la publication sur les bases est possible depuis la fenêtres présentant les propriétés du serveur de publication ,le Choix Propriétés du serveur de publication depuis le menu contextuel associé au nœud Réplication de l’explorateur d’objects permet d’afficher cette fenêtres

La création d’une publication est également réalisée par intermédiaire d’un assistant sous SQL SERVER Management studio Pour crée une nouvelle publication il faut sélectionner Nouvelle Publication

La première étape de l’assistant consiste à sélectionner la base de données qui contient le ou les objets qui vont participer à la publication Cette boite de dialogue montre Toutes les bases de donnée utilisateurs qu’elles soient ou non activées pour la réplication Dans l’exemple ci-dessous, seul la base Production est activée pour la réplication, alors que toutes les bases sont présentes dans la fenêtre
Dans l’étape ci-dessous la publication est définit dans la cadre d’une réplication transactionnelle, c’est-à-dire que les données sont modifiées sur l’éditeur et que ces modifications sont reportés sur les abonnées par le processus de réplication

Après que le type de réplication est défini, il est possible de sélectionner les éléments de la base qui participent à cette publication, c’est-à-dire définir les articles Dans l’exemple ci-dessous, la publication va compter un seul article
Remarque : Seuls les tables qui possèdent une clé primaire peuvent participer à une publication Pour chaque article, il est intéressant d’afficher sa propriété afin de saisir une description pour chaque article et fixer le schéma et le nom de la table Les propriétés de l’article publié permettent de définir le composant a adoptée sur les index ,les valeurs par défaut les autorisations

L’étape suivante permet de définir s’il est nécessaire ou non de réaliser une capture instantanée et éventuellement de planifier la création régulière de nouvelle capture instantanée Ce dernier point est particulièrement intéressant lorsque le volume de données modifiées est important Par la suite l’assistant demande à spécifier les comptes de sécurité qui vont être utilisées par les agents de capture instantanée et de lecture du journal pour se connecter au serveur

Avant de cliquer sur Terminer pour crée la publication, l’assistant offre la possibilité de crée les scripts Transact SQL relatifs à la création de cette nouvelle publication La dernière étape de l’assistant permet de nommer la publication puis de demander sa création

 Après leur création, il est possible de visualiser et de modifier les publication depuis SQL Server Management Studio, il est possible par l’intermédiaire des propriétés de la publication de modifier les Choix définis lors de l’exécution de l’assistant de création de la publication
Après leur création, il est possible de visualiser et de modifier les publication depuis SQL Server Management Studio, il est possible par l’intermédiaire des propriétés de la publication de modifier les Choix définis lors de l’exécution de l’assistant de création de la publication

3-les abonnements S’abonner à une publication signifie que l’abonné accepte les données répliquées sur une base de destination SQL Server Management Studio propose un assistant pour crée de nouveau abonnement, il est possible de lancer cet assistant en sélectionnant l’option Nouveau Abonnement dans le menu contextuel attache soit depuis le nœud Réplication-Abonnement Locaux soit associé à une publication C’est d’ailleurs cette dernière possibilité qui est illustrée par l’écran Ci-dessous
 Ensuite l’assistant demande de préciser le type de l’abonnement c’est-à-dire si l’abonnement sera de type poussé(avec l’exécution de l’agent sur le distributeur) ou bien tiré (avec l’exécution de l’agent sur l(abonné) Dans cette exemple c’est un abonné de type poussée qui est selectioné L’assistant permet ensuite de sélectionner l’abonné Si l’abonné n’apparait pas dans la liste proposée, Il faut utiliser le bouton Ajouter un abonné pour inscrire le serveur de ainsi avoir la possibilité de le Sélectionner en tant qu’abonnée lors de la sélection d’un serveur abonné il faut également spécifier La base de données destinatrice de l’abonnement
Ensuite l’assistant demande de préciser le type de l’abonnement c’est-à-dire si l’abonnement sera de type poussé(avec l’exécution de l’agent sur le distributeur) ou bien tiré (avec l’exécution de l’agent sur l(abonné) Dans cette exemple c’est un abonné de type poussée qui est selectioné L’assistant permet ensuite de sélectionner l’abonné Si l’abonné n’apparait pas dans la liste proposée, Il faut utiliser le bouton Ajouter un abonné pour inscrire le serveur de ainsi avoir la possibilité de le Sélectionner en tant qu’abonnée lors de la sélection d’un serveur abonné il faut également spécifier La base de données destinatrice de l’abonnement

Ensuite, l’assistant demande de préciser les comptes de sécurité qui seront utilisés par l’agent de distribution pour se connecter au serveur de distribution et sur l’abonné
 Par la suite, l’assistant demande de préciser le mode d’exécution de l’agent de distribution, Dans L’exemple présenté ci-dessous l’agent est exécuté en continue de façon à reporter le plus rapidement
Par la suite, l’assistant demande de préciser le mode d’exécution de l’agent de distribution, Dans L’exemple présenté ci-dessous l’agent est exécuté en continue de façon à reporter le plus rapidement

Le même Type de question est posé par l’assistant pour l’exécution de la capture instantané qui peut Être exécuté soit immédiatement soit lors de la première synchronisation

Comme pour la création de la publication l’assistant donne la possibilité de générer les scripts Transact SQL Correspondants
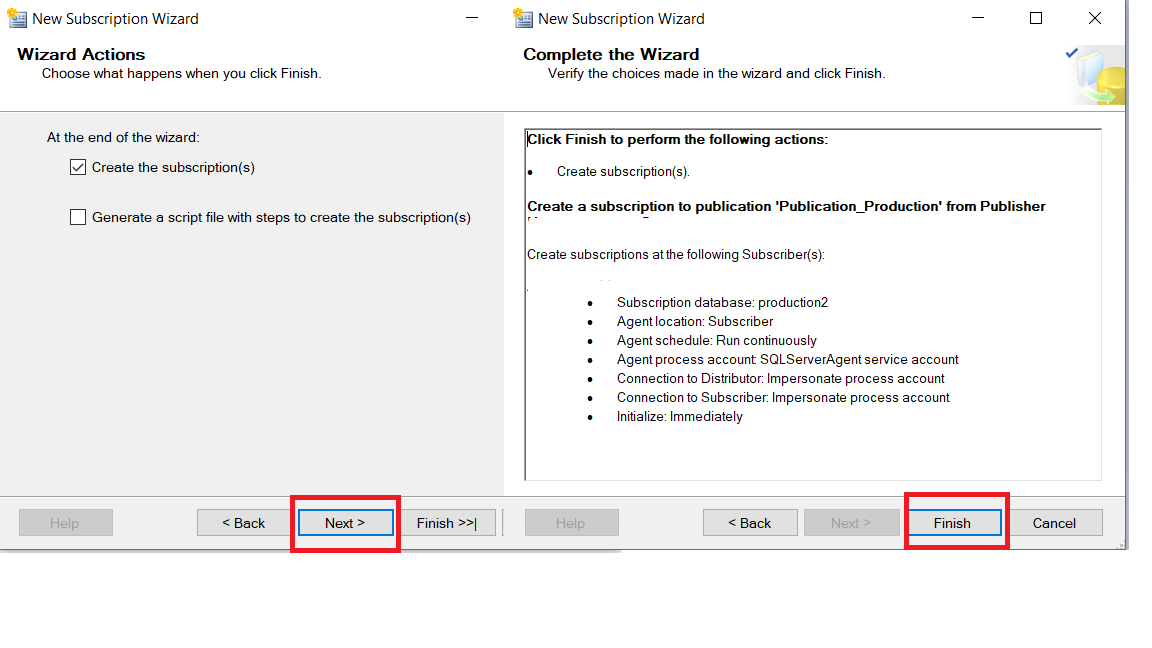 Puis l’assistant présente un écran de synthèse avant de terminer la création de l’abonnement
Puis l’assistant présente un écran de synthèse avant de terminer la création de l’abonnement
Depuis SQL Server il est possible de visualiser l’ensemble des abonnements définis par rapport à une publication mais aussi l’abonnement souscrit localement par le serveur Le moniteur de réplication peut être lancé depuis le distributeur pour suivre le déroulement et l’exécution des différentes agents de la réplication Ce moniteur est accessible en sélectionnant lancer le monitor de réplication depuis le menu contextuel associé au nœud Réplication de l’explorateur d’objets de SQL server Mangement Studio
 Le menu contextuel associé à la publication permet également d’obtenir les comptes rendus d’exécution des agents de capture instantanée et de lecture du journal
Le menu contextuel associé à la publication permet également d’obtenir les comptes rendus d’exécution des agents de capture instantanée et de lecture du journal


4-supression de la réplication
La suppression d’an abonnement empêche les nouvelles mis à jour de la base de destination mais pour autant cette dernière n’est pas supprimée ni même nettoyée il reviendra à un administrateur du serveur de destination de supprimer le schéma crée par la mise en place de la publication
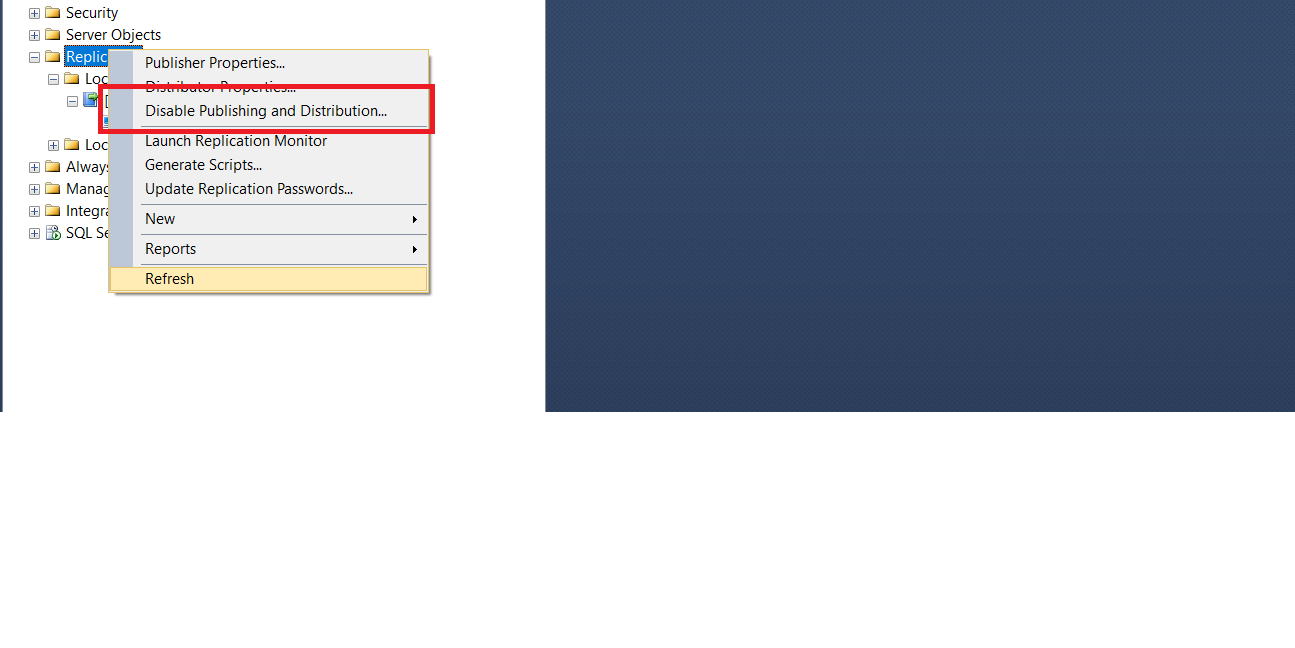
La désinstallation
Il est possible de désinstaller un distributeur par le biais de l’assistant Réplication Réplication , Désactiver l’assistant Publication et Distribution
Les effets sont les suivants :
-les bases de données distribution du serveur sont supprimées
– Toutes les éditeurs qui utilisent ces distributeurs sont désactivés et toutes les publications sont supprimées
– Toutes les abonnements sont supprimés, mais les données d’abonnement restent sur les abonnés


Bonne configuration de la réplication