Il est souvent nécessaire de compresser et de décompresser les fichiers que nous souhaitons traiter avec (SSIS). Il existe plusieurs outils différents dotés de cette fonctionnalité. Dans cette astuce, je montrerai les étapes à suivre pour compresser et décompresser des fichiers à l’aide de 7-Zip dans le cadre d’un package SQL Server Integration Services
Nous pouvons utiliser n’importe quel extracteur de fichier dans SQL Server Integration Services, mais pour cette démonstration, je vais utiliser 7-Zip pour compresser et décompresser des dossiers et des fichiers.
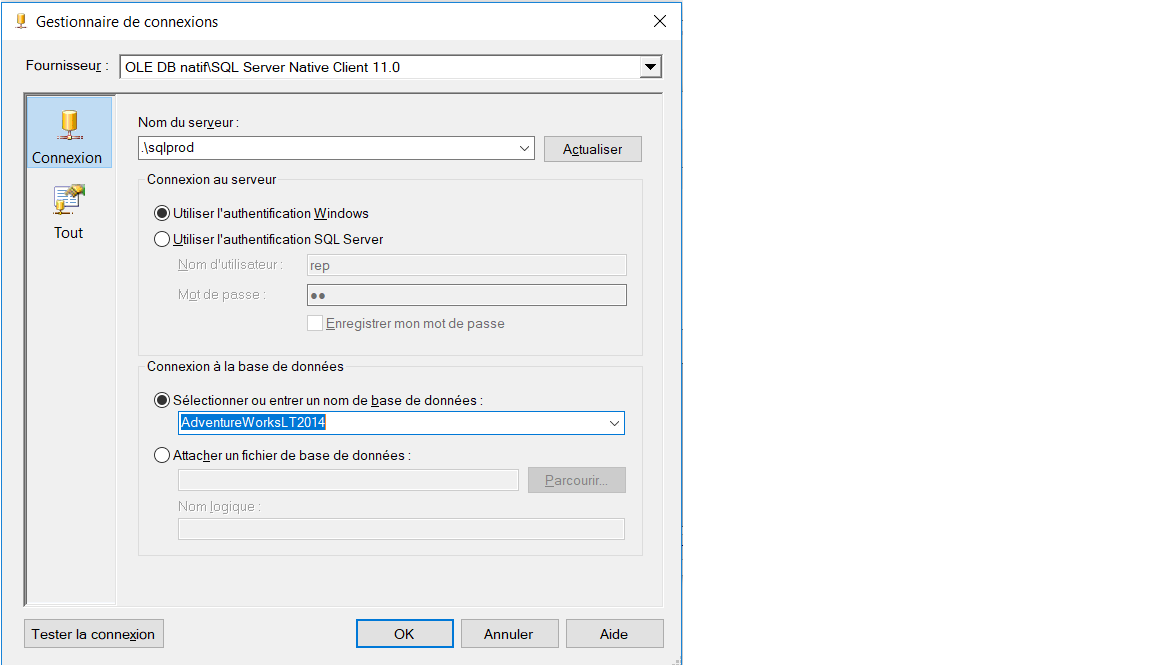
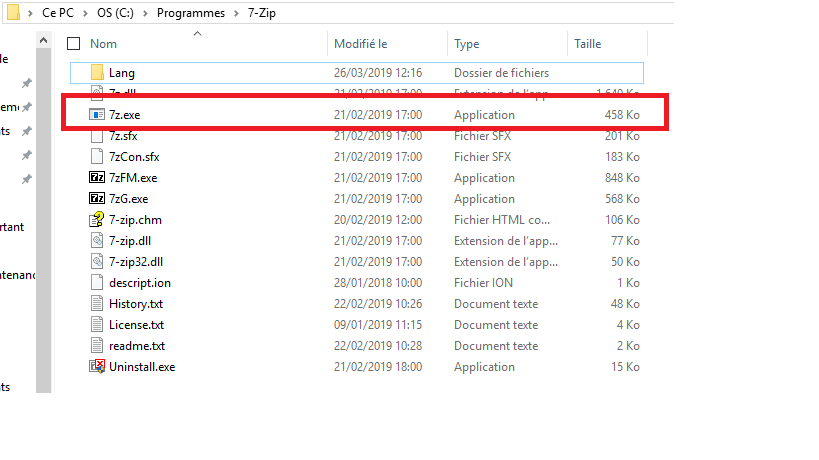
Après avoir installé le 7-Zip sur mon PC, voici l’emplacement d’installation de 7-Zip
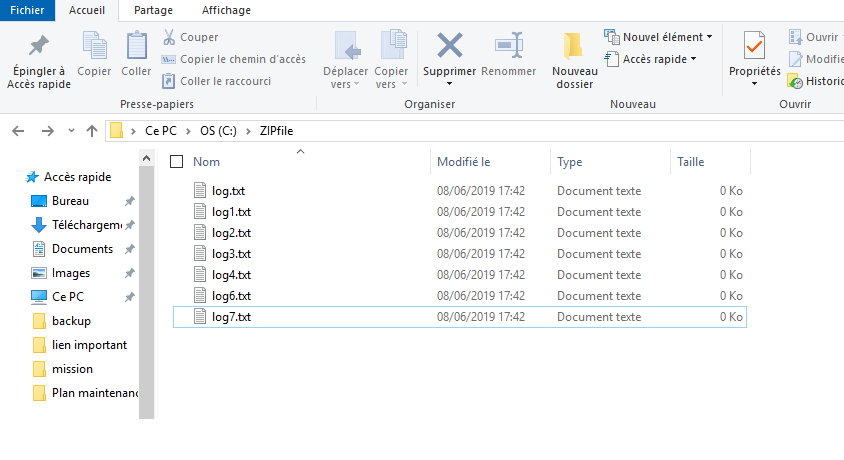
Ceci est l’emplacement où je veux compresser les fichiers.
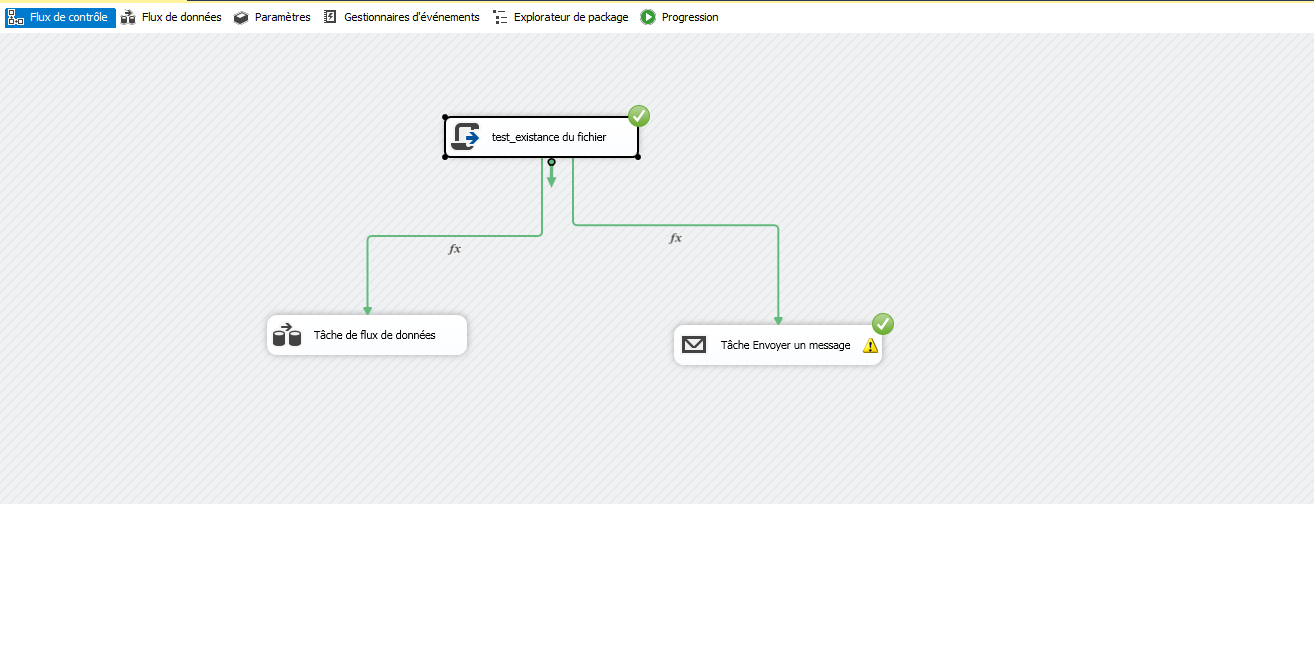
Maintenant j’ai fait glisser une tâche d’exécution de processus de la boîte à outils SSIS vers le flot de contrôle et l’a renommé » ZIP Data « .
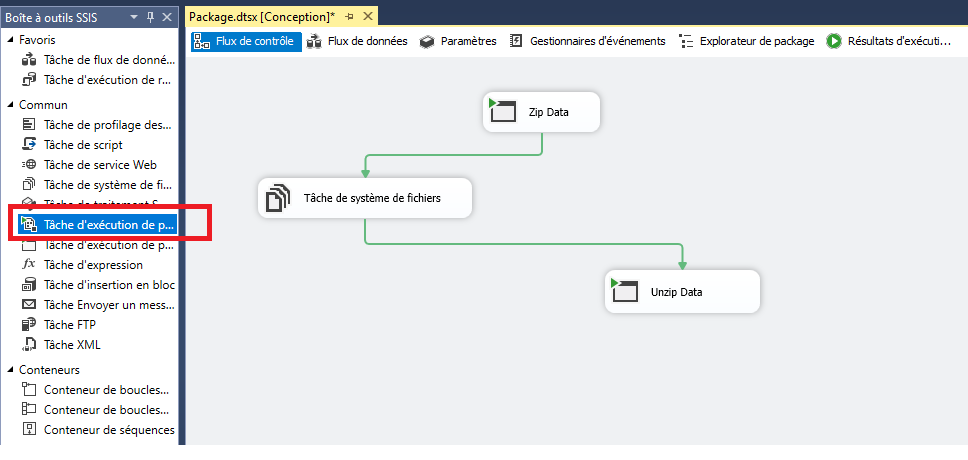
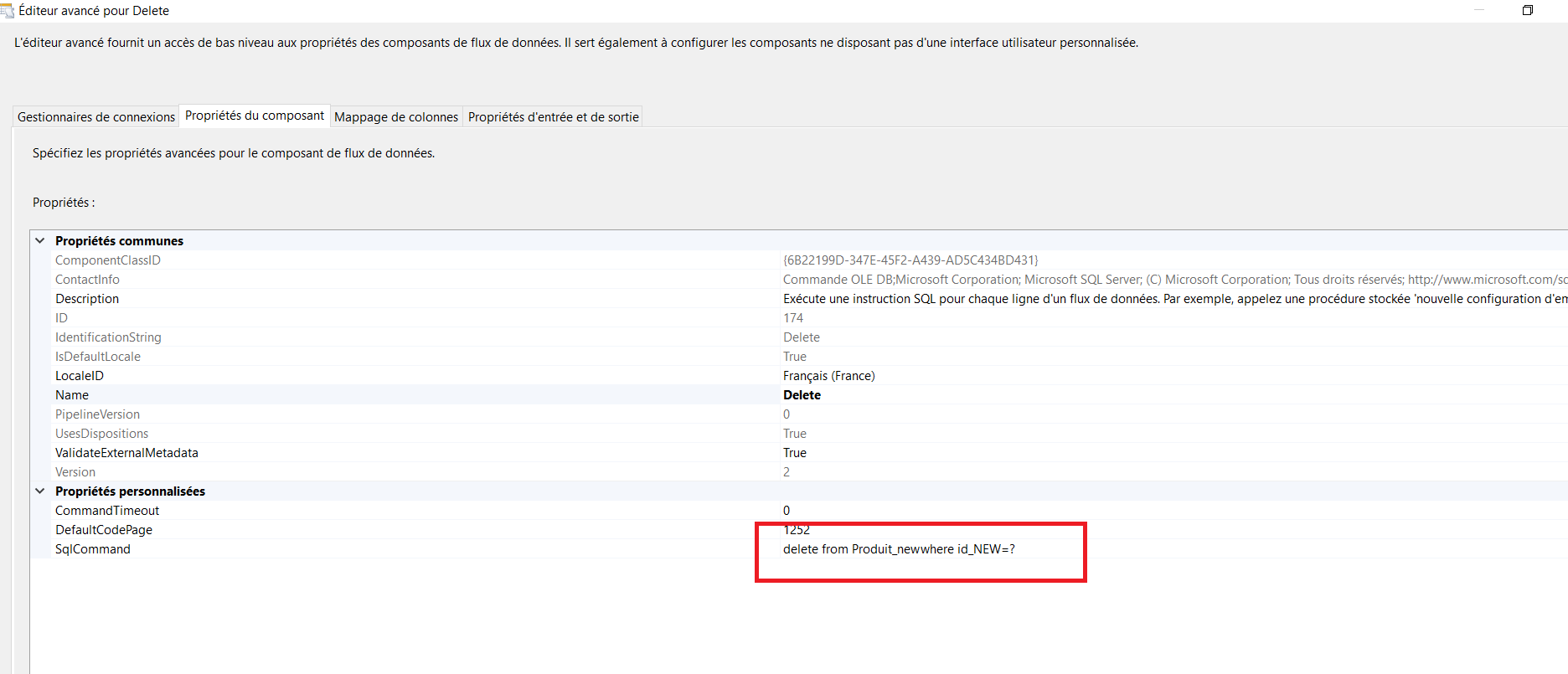
Maintenant, faites un clic droit sur la tâche et choisissez « Modifier … » pour ouvrir l’éditeur de tâche d’exécution, puis cliquez sur « Processus » à gauche et modifiez le chemin de l’exécutable, les arguments et le répertoire de travail comme suit et conservez les autres comme valeurs par défaut. Je l’explique plus bas
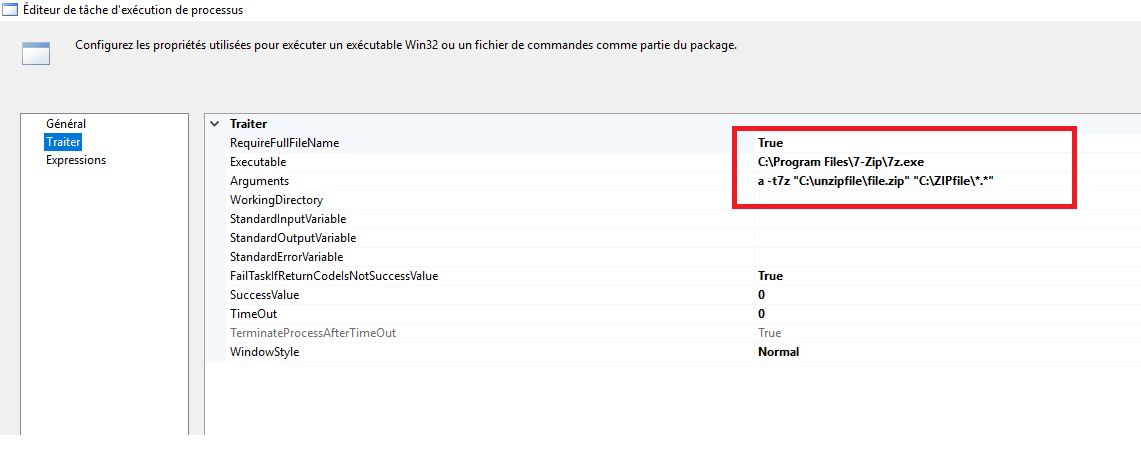
Exécutable
Placez le chemin complet de l’exécutable en tant que: C: \ Program Files \ 7-Zip \ 7z.exe*
Arguments
Fournissez les arguments d’invite de commande: a -t7z « C:\unzipfile\file.zip » « C:\ZIPfile*.* »
- Je vais archiver les fichiers en utilisant l’ argument de commande « a » .
- Le format est spécifié avec le commutateur -t -t7z
- Placez tous les fichiers dans le fichier zip « C:\unzipfile\file.zip «
- De l’emplacement « C:\ZIPfile «
Exécution du package SSIS dans des fichiers Zip
Le paquet est maintenant configuré pour l’archivage des données.
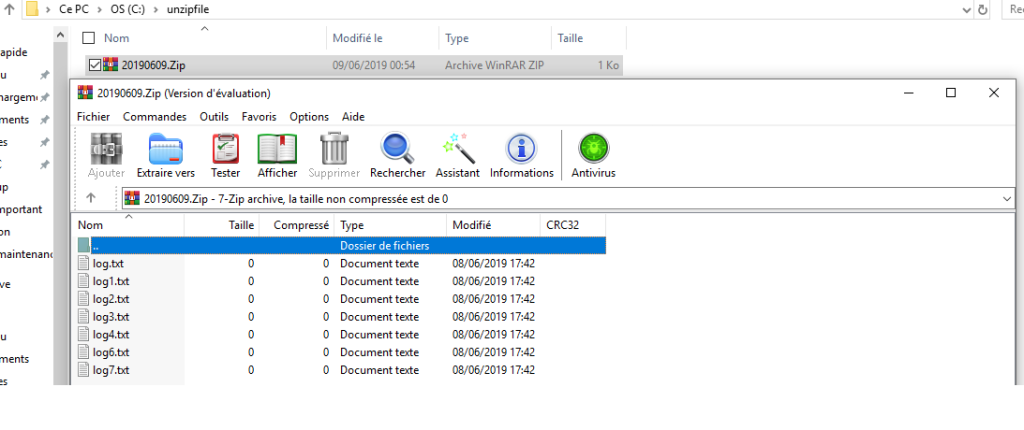
Selon la configuration, tous les fichiers sont compressés dans BulkFiles sur le lecteur c:\
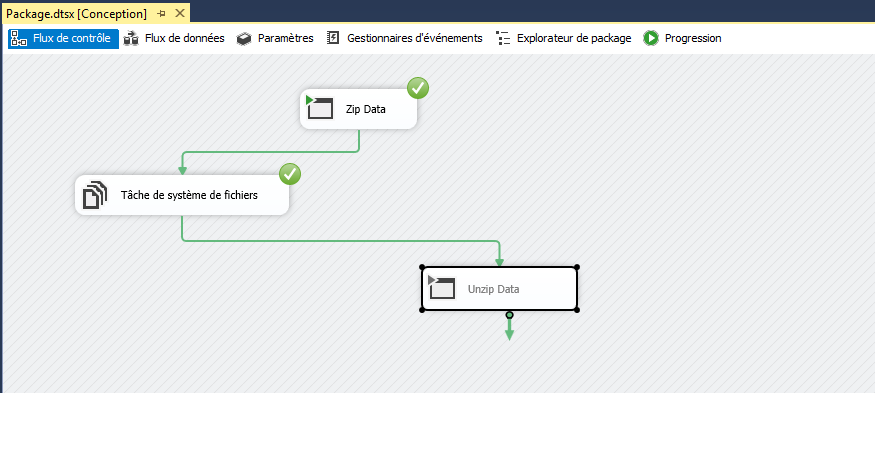
J’ai ajouterai au package SSIS une autre tâche d’exécution de processus pour extraire les fichiers que nous venons de compresser.
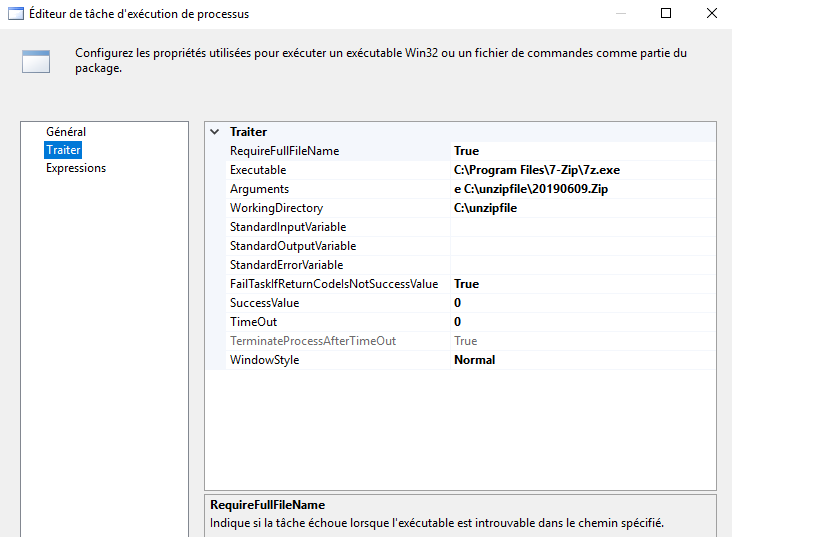
Voici les paramètres pour décompresser les fichiers.
Exécutable
Placez le chemin complet de l’exécutable en tant que: C: \ Program Files \ 7-Zip \ 7z.exe
Je vais extraire les fichiers en utilisant l’ argument de la commande « e »
j’utilise un argument pour gérer le changement dynamique du nom

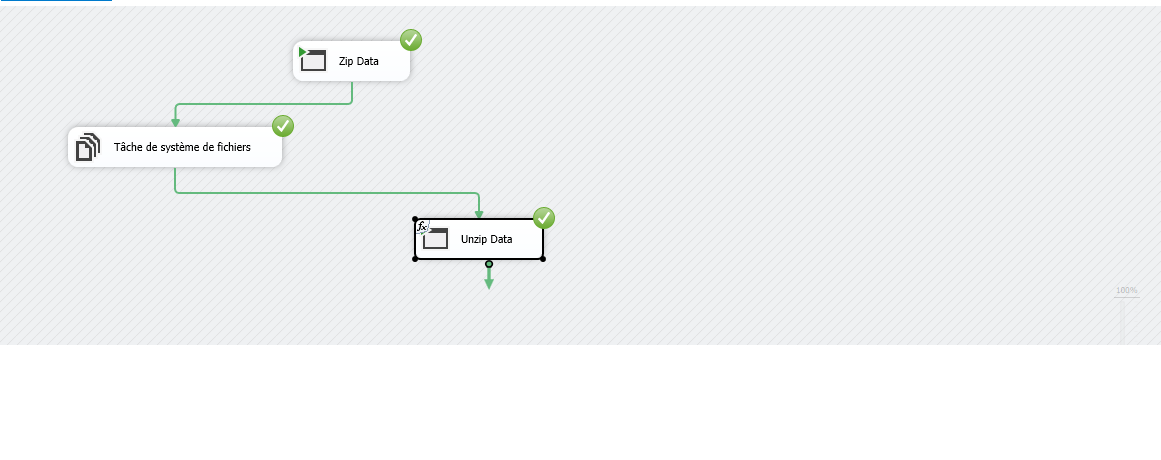
Exécution du package SSIS pour décompresser des fichiers
Voici le paquet
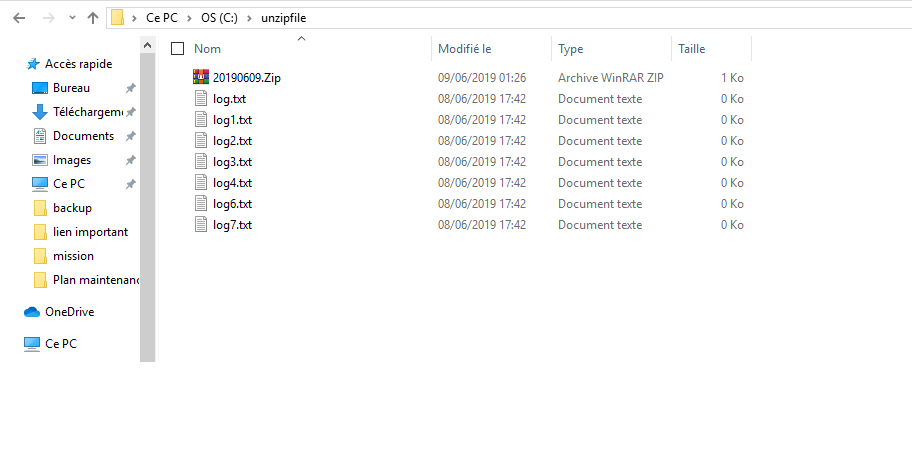
Si nous regardons le lecteur c: \unzipfile , nous pouvons voir les fichiers extraits.
Bonne lecture