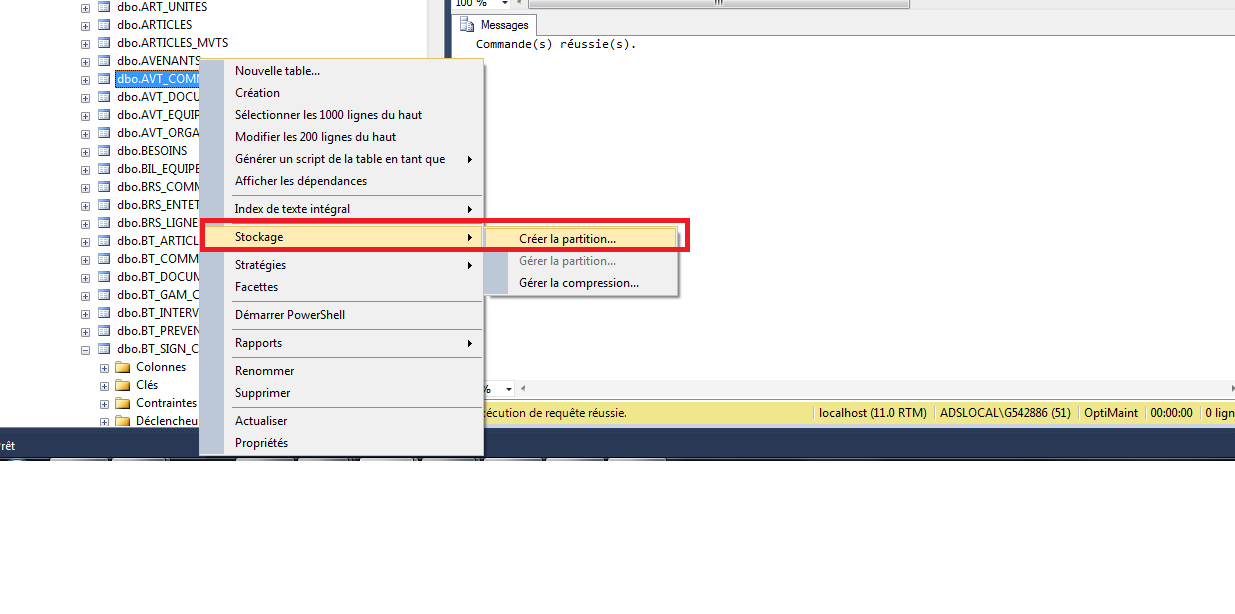
bonjour a tous
Si vois été intéresser de s’avoir l’espace occupé par vos index alors c’est ce script qui vous permet de trouver la taille de tous vos index dans une base de donnée avec la table et le groupe de fichiers sur lequel réside l’index J’utilise la base de données AdventureWorks2012 à titre d’exemple. S’il vous plaît remplacer le nom DB pour lequel vous voulez trouver l’information
USE AdventureWorks2012
go
IF OBJECT_ID('tempdb..#Indexdata', 'U') IS NOT NULL
DROP TABLE #Indexdata
DECLARE
@SizeofIndex BIGINT, @IndexID INT,
@NameOfIndex nvarchar(200),@TypeOfIndex nvarchar(50),
@ObjectID INT,@IsPrimaryKey INT,
@FGroup VARCHAR(20)
create table #Indexdata (name nvarchar(50),
IndexID int, IndexName nvarchar(200),
SizeOfIndex int, IndexType nvarchar(50),
IsPrimaryKey INT,FGroup VARCHAR(20))
DECLARE Indexloop CURSOR FOR
SELECT idx.object_id, idx.index_id, idx.name, idx.type_desc
,idx.is_primary_key,fg.name
FROM sys.indexes idx
join sys.objects so
on idx.object_id = so.object_id JOIN sys.filegroups fg
ON idx.data_space_id = fg.data_space_id
where idx.type_desc != 'Heap'
and so.type_desc not in ('INTERNAL_TABLE','SYSTEM_TABLE')
OPEN Indexloop
FETCH NEXT FROM Indexloop
INTO @ObjectID, @IndexID, @NameOfIndex,
@TypeOfIndex,@IsPrimaryKey,@FGroup
WHILE (@@FETCH_STATUS = 0)
BEGIN
SELECT @SizeofIndex = sum(avg_record_size_in_bytes * record_count)
FROM sys.dm_db_index_physical_stats(DB_ID(),@ObjectID,
@IndexID, NULL, 'detailed')
insert into #Indexdata(name, IndexID, IndexName, SizeOfIndex,
IndexType,IsPrimaryKey,FGroup)
SELECT TableName = OBJECT_NAME(@ObjectID),
IndexID = @IndexID,
IndexName = @NameOfIndex,
SizeOfIndex = CONVERT(DECIMAL(16,1),(@SizeofIndex/(1024.0 * 1024))),
IndexType = @TypeOfIndex,
IsPrimaryKey = @IsPrimaryKey,
FGroup = @FGroup
FETCH NEXT FROM Indexloop
INTO @ObjectID, @IndexID, @NameOfIndex,
@TypeOfIndex,@IsPrimaryKey,@FGroup
END
CLOSE Indexloop
DEALLOCATE Indexloop
select name as TableName, IndexName, IndexType,
SizeOfIndex AS [Size of index(MB)],
case when IsPrimaryKey = 1 then 'Yes' else 'No' End as [IsPrimaryKey]
,FGroup AS [File Group]
from #Indexdata order by SizeOfIndex DESC

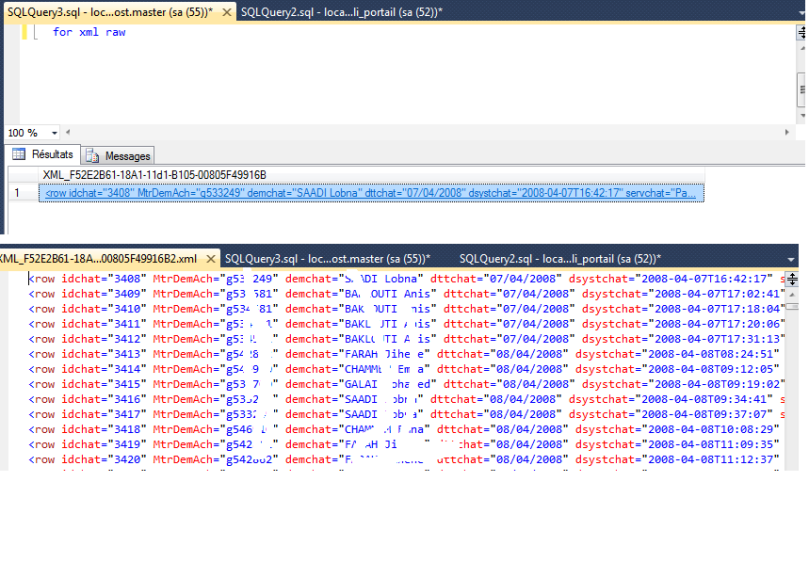 for xml path
for xml path



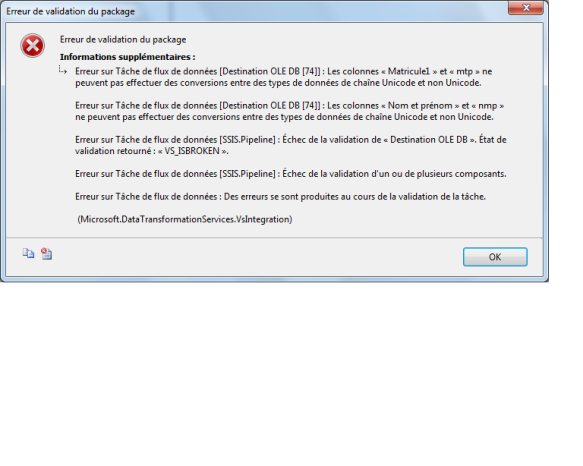
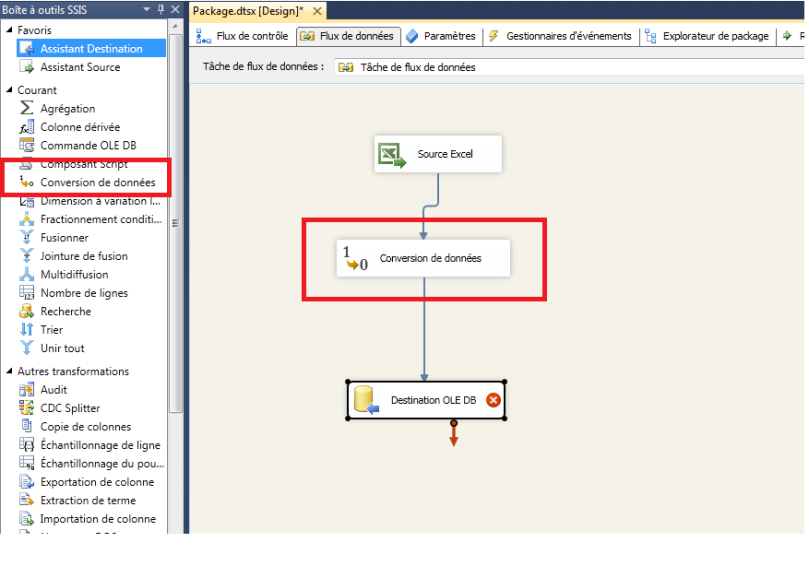
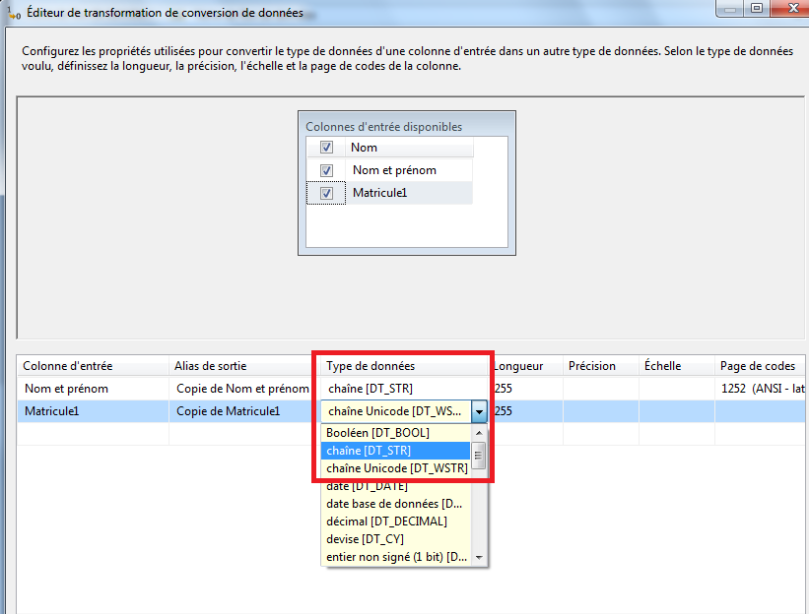
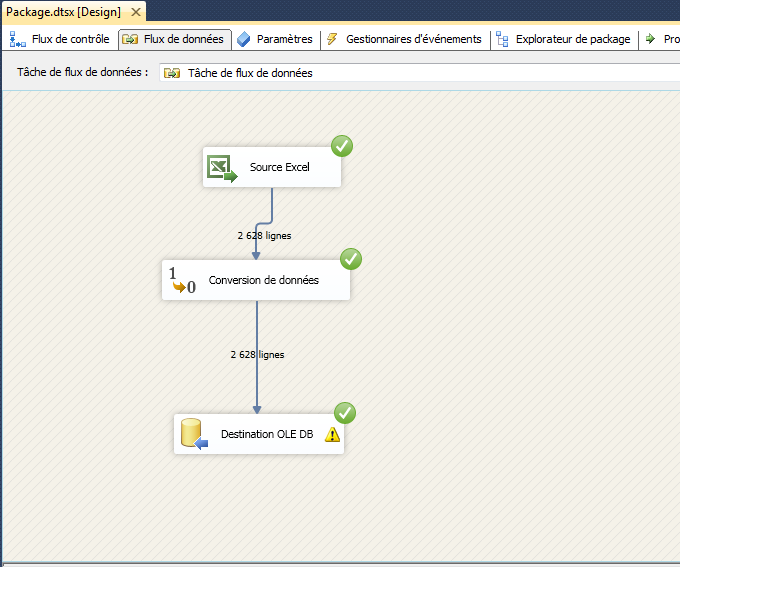 Remarque Lorsque vous utilisez l’Assistant Importation et Exportation SQL Server pour créer un package, l’Assistant crée et configure toutes les transformations de conversion de données dont vous avez besoin
Remarque Lorsque vous utilisez l’Assistant Importation et Exportation SQL Server pour créer un package, l’Assistant crée et configure toutes les transformations de conversion de données dont vous avez besoin