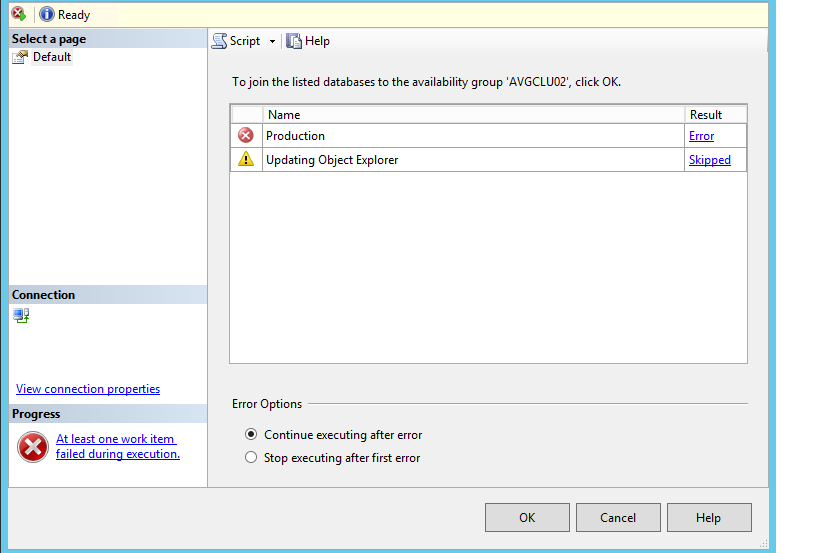
L’Agent SQL Server ne fait pas partie de l’AG en Faite Les groupes de disponibilité AlwaysOn synchronisent les bases de données qui font partie d’un groupe de disponibilité, mais tout autre objet qui ne fait pas partie de ces bases de données n’est pas synchronisé (c’est-à-dire les connexions, les serveurs liés, les opérateurs, etc.) et cela inclut les travaux de l’Agent SQL Server.
Pour accomplir ce mode de création de travail d’agent SQL, j’utilise cette fonction pour tester si une base de données participe à un AG est accessible en écriture. Si c’est le cas, passez au reste des étapes du travail de l’agent SQL. Si ce n’est pas le cas, stopper le job
-- fn_hadr_group_is_primary
USE master;
GO
IF OBJECT_ID('dbo.fn_hadr_group_is_primary', 'FN') IS NOT NULL
DROP FUNCTION dbo.fn_hadr_group_is_primary;
GO
CREATE FUNCTION dbo.fn_hadr_group_is_primary (@AGName sysname)
RETURNS bit
AS
BEGIN;
DECLARE @PrimaryReplica sysname;
SELECT
@PrimaryReplica = hags.primary_replica
FROM sys.dm_hadr_availability_group_states hags
INNER JOIN sys.availability_groups ag ON ag.group_id = hags.group_id
WHERE ag.name = @AGName;
IF UPPER(@PrimaryReplica) = UPPER(@@SERVERNAME)
RETURN 1; -- primary
RETURN 0; -- not primary
END;
Utilisez la fonction fn_hadr_group_is_primary dans une nouvelle étape de travail pour déterminer si cette instance sql est un réplica principal. S’il ne s’agit pas d’un réplica principal, nous émettons une demande d’arrêt de la tâche tout en identifiant le nom de la tâche actuelle à l’aide des jetons de l’agent SQL Server.
-- Detect if this instance's role is a Primary Replica.
-- If this instance's role is NOT a Primary Replica stop the job so that it does not go on to the next job step
DECLARE @rc int;
EXEC @rc = master.dbo.fn_hadr_group_is_primary N'my-ag';
IF @rc = 0
BEGIN;
DECLARE @name sysname;
SELECT @name = (SELECT name FROM msdb.dbo.sysjobs WHERE job_id = CONVERT(uniqueidentifier, '$(ESCAPE_NONE(JOBID))'));
EXEC msdb.dbo.sp_stop_job @job_name = @name;
PRINT 'Stopped the job since this is not a Primary Replica';
END;