bonjour
Aujord’huit j’ai eu une réclamation envoyer par la production sur la présence d’un problème du lenteur détecter dans les lignes du productions
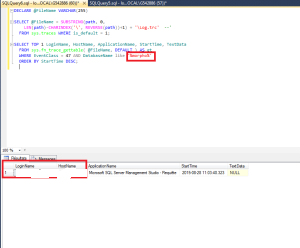
on analysant le problème je viens de trouver que le problème viens d’une requête d’extraction ci joint leur syntaxe
La requête en question :SELECT count(distinct([Board_ID])) FROM Location where Inspection_end_time between ‘2015-08-27 14:00:00’ and ‘2015-08-27 22:00:00’
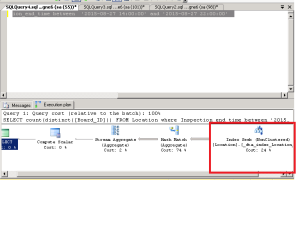
Le plan de requête généré est le suivant :
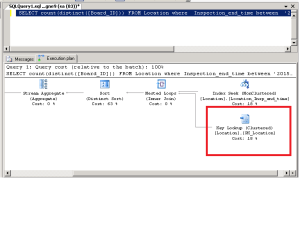
Ce qu’on peut déduire, c’est que l’optimiseur de requête a utilisé l’index non-cluster « IX_**** » pour identifier chaque ligne qui correspond aux critères de la requête. Et une fois l’index non-cluster utilisé, il a procédé à la recherche des informations desdites lignes de la colonne indexée en utilisant l’index en cluster. On parle alors de recherche sur clé, ou key lookup . Dans le cas d’une table sans index en cluster, on parle de RID lookup (ou recherche sur identifiant de ligne(voir le carré en rouge)
j’ai procéder donc a cré un index NONCLUSTERED en ajoutant le colonne [Inspection_end_time] [Location_ID] ,[Board_ID] afin d’assurer une couverture de la totalité de ma requête
Ci joint le syntaxe du script d’index
« CREATE NONCLUSTERED INDEX [_dta_index_Location_9_1765581328__K6_K1_K4] ON [dbo].[Location]
(
[Inspection_end_time] ASC,
[Location_ID] ASC,
[Board_ID] ASC
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [PRIMARY] »
Jetons, maintenant, un coup d’œil au plan d’exécution de la requête :
Ci joint Le nouveau plan du requête généré :
Bref, on a gagné près de 50%…
On peut noter la réduction de la consommation des ressources I/O. En effet, en utilisant un seul index contenant toutes les informations qu’il recherche, l’optimiseur gagne beaucoup de temps lors du traitement de la requête
Un index contenant des colonnes non-clés peut améliorer considérablement les performances des requêtes lorsque toutes les colonnes de la requête sont incluses dans l’index en tant que colonnes clés ou non-clés.Les gains de performances sont due au fait que l’optimiseur de requête peut localiser toutes les valeurs des colonnes dans l’index ; l’accès aux données de table et d’index n’a pas lieu, produisant ainsi un nombre moindre d’opérations d’E/S sur le disque
Lorsqu’un index contient toutes les colonnes auxquelles une requête fait référence, on dit qu’il couvre la requête.(index couvrant)
Dans le cadre d’un index couvrant, le moteur privilégiera le parcours de l’arbre d’index plutôt que le scan de la table, d’où l’optimisation
cordialement