
bonjour
Un des objectifs des bases de données est de stocker l’information tout en l’organisant de manière à pouvoir y accéder rapidement il y a plusieurs manières d’accéder à l’information. Pour accéder à une ligne donnée d’une table
Postgresql dispose de plusieurs solutions que nous expliquerons sous peu. Citons parmi celles-ci par exemple le « parcours complet de table » ou « seq scan« , le « parcours d’index » ou « Seq index » … ou aussi Index partiels c’est ce dont nous allons parler aujourd’hui
Un index partiel est un index construit sur un sous-ensemble d’une table ; le sous-ensemble est défini par une expression conditionnelle (appelée prédicat de l’index partiel). L’index ne contient des entrées que pour les lignes de la table qui satisfont au prédicat. Les index partiels sont une fonctionnalité spécialisée, mais ils trouvent leur utilité dans de nombreuses situations.
Un index partiel est utile pour les conditions where fréquentes qui utilisent des valeurs constantes
voyant cette petit exemple
with cte as(select row_number()over(partition by matricule order by date_capture)as classement ,person_id,matricule,template,date_capture,First_name,last_name from finger_print fp INNER JOIN person p on fp.person_id=p.id where finger_type='Segma' )select * from cte where classement=1 order by date_capture desc
le plan d’execution du cette requéte avec aucun index montre une opération de type scan_table avec un coût d’exécution de 2820ms
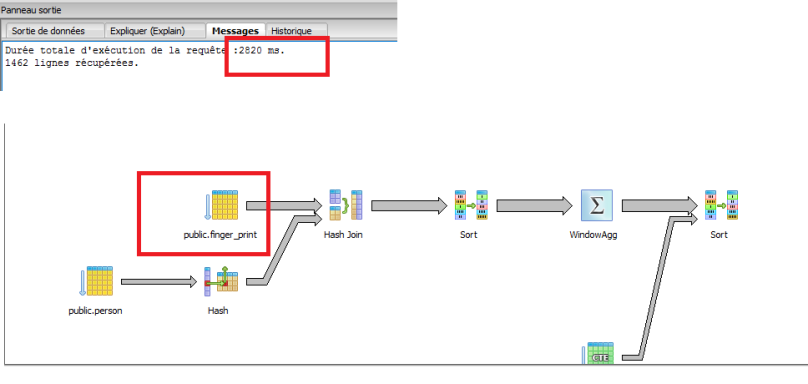
commençons a jouer avec les choses en ajoutant cette petit index
create index indexe_partiel on finger_print(finger_type) where finger_type=’Segma’
ci joint le nouveau plan exécution, régénérer et le temps a été minimiser vers 213ms
et l’opération scan_table a été remplacer par un scan_index et non pas n’importe quel index mais un index partiel
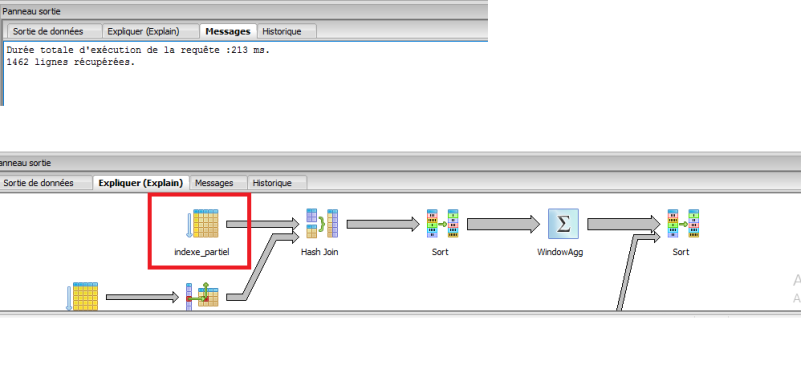
Une base de données peut utiliser un index partiel à chaque fois qu’une clausewhere apparaît dans une requête
bonne optimisation
