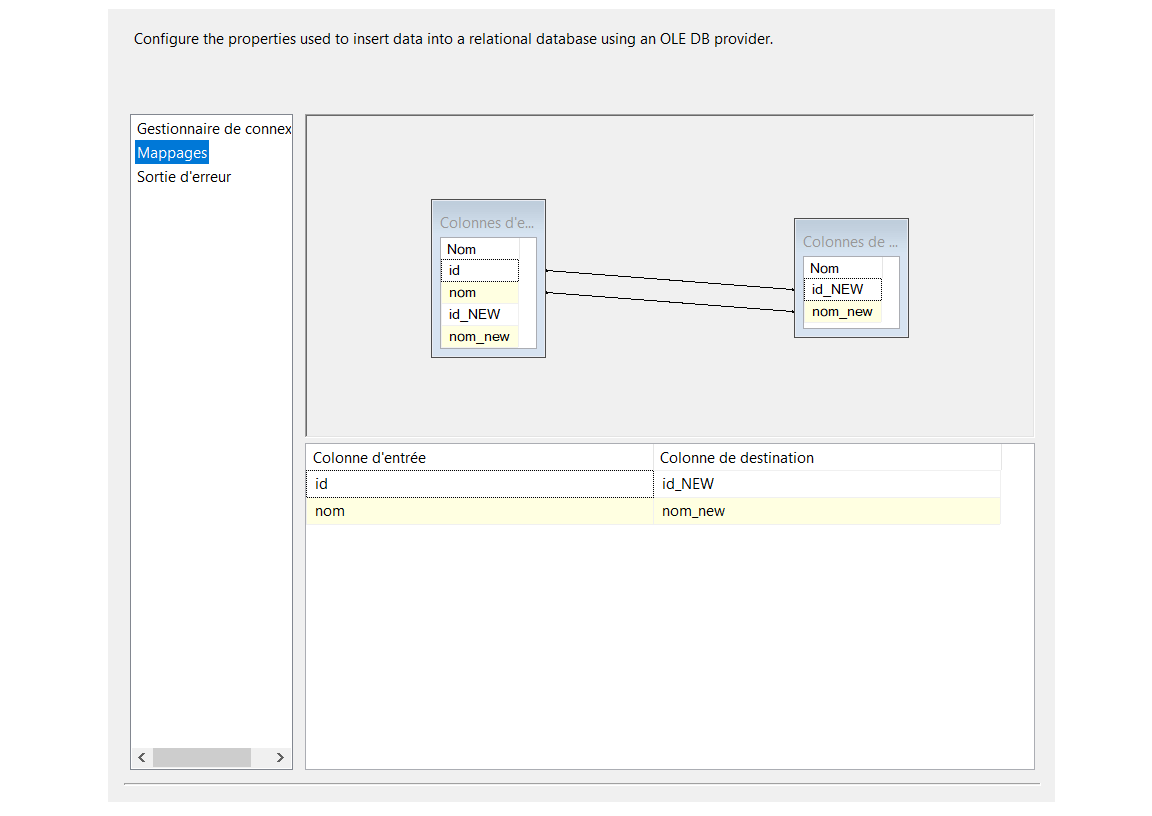
J’ai été en train de configurer un environnement SQL Server AlwaysOn à deux nœuds. Lors de la configuration, nous avons reçu »
Error: 1408 Joining database on secondary replica resulted in an error. » Comment cette erreur s’est-elle produite et comment la résolvons-nous?
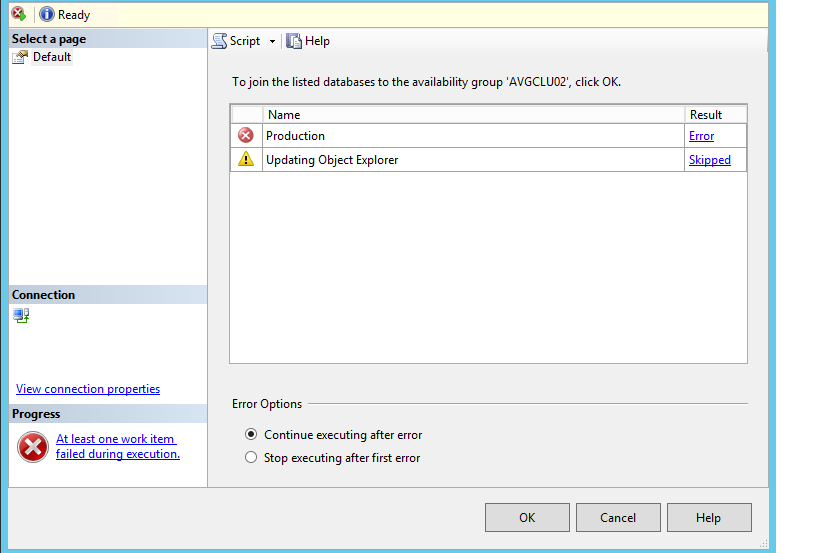
Vous pouvez voir ici que SQL Server AlwaysOn a été configuré avec succès sur le réplica secondaire xxxx, alors qu’une erreur s’est produite pour le réplica secondaire xxxx. Nous allons maintenant vérifier les détails de l’erreur pour résoudre ce problème. Vous pouvez cliquer sur le lien « Erreur » pour obtenir les détails de l’erreur, comme indiqué dans la capture d’écran ci-dessous.

vous verrez que la base de données posant problème comporte un point d’exclamation. Faites un clic droit sur cette base de données et cliquez sur «Rejoindre un groupe de disponibilité»
Maintenant, si vous lancez le rapport de tableau de bord SQL Server AlwaysOn, vous pouvez voir l’état actuel de la configuration AlwaysOn, comme indiqué dans la capture d’écran ci-dessous.

Les détails de l’erreur indiquent que « la copie distante de la base de données » DRTest « n’est pas récupérée suffisamment pour permettre la mise en miroir de la base de données ou pour la joindre au groupe de disponibilité. Vous devez appliquer les enregistrements de journal manquants à la base de données distante en restaurant le fichier en cours. enregistrer les sauvegardes de la base de données principale / principale. (Microsoft SQL Server, Erreur: 1408) « . Cela signifie que les bases de données source et cible ne sont pas synchronisées. Nous allons résoudre ce problème dans cette astuce. Cliquez sur le bouton OK pour fermer cette fenêtre.

Alter database production SET HADR AVAILABILITY GROUP = AVGProduction;
Msg 1478, Level 16, State 101, Line 1
The mirror database, « XXXXX », has insufficient transaction log data to preserve the log backup chain of the principal database. This may happen if a log backup from the principal database has not been taken or has not been restored on the mirror database.
Vous devez restaurer la sauvegarde du journal qui a été prise à partir de la base de données primaire vers la base de données secondaire et réessayer. Si vous ne trouvez pas la sauvegarde du journal ou si vous avez effectué la sauvegarde avec une autre application de sauvegarde, effectuez une sauvegarde différentielle, puis effectuez une sauvegarde du journal à partir de la base de données principale et restaurez ces sauvegardes dans la base de données secondaire en mode Norecovery
cliquez avec le bouton droit de la souris sur la base de données secondaire dans l’onglet Bases de données de disponibilité, puis cliquez sur « Join To Avaibility Groupe »
. Au bout d’un moment, vous constaterez que l’état de la base de données secondaire est à nouveau synchronisé et que le problème est corrigé.

on passe maintenant à la réplique principale xxxxxx et lancez le rapport de tableau de bord SQL Server AlwaysOn pour cette configuration. Le rapport de tableau de bord du groupe de disponibilité « xxxxx » apparaît dans le volet de droite. L’état du groupe de disponibilité est maintenant sain et toutes les valeurs d’état sont vertes. Vous pouvez valider la configuration de la réplique secondaire xxxxx ainsi que celle illustrée ci-dessous.